「AIが嘘をつく」を解決する技術 — 検索拡張生成(RAG)の全体像
チャンキング・エンベディング・ベクトルDB・ハイブリッド検索まで、2026年最新の実装知識を網羅。
この記事でわかること
RAG(Retrieval-Augmented Generation)は、生成AIに「正しい情報源」を渡してから回答させる仕組みです。本記事では、RAGの基本概念からチャンキング・エンベディング・ベクトルデータベースといった構成要素、検索精度を高めるテクニック、そして2026年最新のAgentic RAGやGraph RAGまで、企業のAI活用に必要な知識を体系的に整理しました。
RAGとは何か — 「教科書持ち込みOK」のAI
RAG(Retrieval-Augmented Generation)は、日本語で「検索拡張生成」と訳されます。2020年にMeta AI Research(旧Facebook AI Research)が発表した論文で提唱された技術で、生成AIが回答を作る前に、関連する情報を外部のデータソースから検索・取得し、その情報を参照しながら回答を生成する仕組みです。
わかりやすく言えば、「教科書持ち込みOKの試験」をイメージしてください。
RAGの本質を試験に例えると
従来のLLMとRAG搭載のLLMの違いを、試験のメタファーで整理すると次の2つに集約できます。
- 従来のLLM(教科書持ち込みNGの試験) — 学習時に覚えた知識だけで回答する。記憶にないことは「わかりません」と答えるか、あるいは自信満々に間違った回答を生成してしまう(ハルシネーション)
- RAG搭載のLLM(教科書持ち込みOKの試験) — 質問を受け取ったら、まず教科書(社内文書やFAQ)の中から関連するページを探し、そのページを参照しながら回答する。根拠のある回答ができる
たとえば、社内の就業規則についてAIに質問したとします。通常のLLMは自社の就業規則を学習していないため、「一般的には〜」という曖昧な回答しかできません。最悪の場合、存在しない規則をもっともらしく生成してしまいます。RAGを導入すれば、AIは質問を受けた瞬間に就業規則のPDFから関連する条文を検索し、その内容に基づいた正確な回答を返すことができます。
RAGが解決する根本的な課題は、LLMの「知識の限界」です。どれだけ優秀なLLMでも、学習データに含まれていない情報 — つまり自社の社内文書、最新のニュース、専門領域の非公開資料 — については回答できません。RAGはこの限界を、「知らないなら調べてから答える」というシンプルなアプローチで突破します。
なぜ今RAGが注目されるのか
ChatGPTの登場以降、多くの企業が「社内データを活用したAIチャットボット」に関心を寄せています。しかし、実際にLLMを業務で使い始めると、すぐにいくつかの壁にぶつかります。RAGはこれらの壁を突破するための現実的な解決策として、急速に注目を集めています。
LLMの学習データに自社情報は含まれない
GPT-5.5やClaude Opus 4.7といった最新LLMは、インターネット上の膨大なテキストを学習しています。しかし、その学習データには自社の社内規定、議事録、顧客情報、製品マニュアルは含まれていません。LLMは「世界の一般知識」には詳しくても、「あなたの会社の業務」は何も知らないのです。
ハルシネーション問題の深刻化
LLMは「知らない」と正直に認める代わりに、もっともらしい嘘を自信満々に回答することがあります。これがハルシネーション(幻覚)です。たとえば「当社の有給休暇の付与日数は?」と聞かれたLLMが、自社の規定を知らないまま「入社6ヶ月後に10日間付与されます」と一般的な回答を返した場合、それが自社の規定と合っている保証はありません。
RAGでは、回答の根拠となる文書を明示できるため、ハルシネーションを大幅に抑制できます。AIが「就業規則第15条に基づき、入社1年後に12日間付与されます」と出典付きで回答すれば、人間がその根拠を確認することも容易です。
ファインチューニングより低コスト・低リスク
「自社データをLLMに学習させればいいのでは?」と考える方もいるでしょう。これはファインチューニングと呼ばれる手法ですが、コスト・技術的難易度・データ鮮度の面でRAGに劣るケースがほとんどです(詳しくはセクション8で比較します)。RAGはLLMの重みを変更せず、「検索して渡す」だけなので、明日からでも始められます。
2026年、エンタープライズAIの主流アーキテクチャに
2026年時点で、企業向けAIソリューションの大半がRAGアーキテクチャを採用しています。Microsoft Copilot、Salesforce Einstein、Google Vertex AI Searchなど、主要プラットフォームがRAGを内部的に利用しており、「RAGを知らずにAI導入を語ることはできない」状況です。
RAGが選ばれる4つの理由
RAGがエンタープライズAIの主流となった背景には、以下の4つの実務的な利点があります。
- データの鮮度 — 新しい文書を追加するだけで、即座にAIの回答に反映される
- コスト効率 — LLMの再学習が不要。ベクトルDBの運用コストのみ
- 透明性 — 「どの文書を根拠に回答したか」を示せるため、監査や説明責任に対応しやすい
- セキュリティ — 機密データをLLMに学習させる必要がなく、アクセス制御を維持できる
RAGの全体フロー — データ準備から回答生成まで
RAGは大きく「データ準備フェーズ」と「質問応答フェーズ」の2段階に分かれます。以下のフローで全体像を把握しましょう。
データ準備フェーズ(事前処理)
RAGを動かす前にあらかじめ実行する、ドキュメントをベクトルDBに登録するまでの工程です。
- ①ドキュメント準備 — 社内文書・FAQ・マニュアルを収集
- ②チャンキング — 文書を小さな塊に分割
- ③エンベディング — テキストをベクトルに変換
- ④ベクトルDB保存 — Pinecone / Weaviate等に格納
質問応答フェーズ(リアルタイム処理)
ユーザーから質問が来たときに動く、検索からLLM回答生成までのリアルタイム処理です。
- ⑤ユーザー質問 — 自然言語で入力
- ⑥ベクトル変換 — 質問を同じ空間に変換
- ⑦類似度検索 — 関連チャンクを取得
- ⑧プロンプト拡張 — 質問+取得情報をLLMへ
- ⑨LLM回答生成 — 根拠に基づく回答
各ステップの役割
①ドキュメント準備 — RAGの品質は、入力するドキュメントの品質で決まります。社内規定、業務マニュアル、FAQ、過去の問い合わせ対応履歴、製品仕様書など、AIに参照させたいあらゆる文書がここに含まれます。PDF、Word、HTML、テキストファイルなど、さまざまな形式から文字情報を抽出します。
②チャンキング — 抽出したテキストを、検索に適した小さな塊(チャンク)に分割します。100ページの就業規則をそのまま保存しても検索には使えません。「有給休暇に関する条文」「育児休業に関する条文」のように、意味のある単位で分割することで、必要な情報だけをピンポイントで取得できるようになります。(詳細はセクション4)
③エンベディング — 分割したテキストチャンクを、数百〜数千次元のベクトル(数値の配列)に変換します。「有給休暇は年間20日付与」というテキストが [0.23, -0.45, 0.78, ...] のような数値列になります。これにより、テキスト同士の「意味的な近さ」を数学的に計算できるようになります。(詳細はセクション5)
④ベクトルDB保存 — 変換したベクトルを、類似度検索に特化したデータベースに保存します。通常のRDBでは数万〜数百万のベクトル間の類似度計算は非常に遅くなりますが、ベクトルDBはこの処理に最適化されており、ミリ秒単位で検索結果を返します。(詳細はセクション6)
⑤ユーザー質問 — ユーザーが「有給休暇の付与日数は?」のように自然言語で質問を入力します。
⑥ベクトル変換 — ユーザーの質問文を、③と同じエンベディングモデルを使ってベクトルに変換します。同じモデルを使うことで、質問のベクトルとドキュメントのベクトルが同じ空間上に配置され、比較可能になります。
⑦類似度検索 — ベクトルDB内で、質問ベクトルと最も近いチャンクベクトルを検索します。コサイン類似度やユークリッド距離といった計算手法を使い、「意味的に最も関連性の高い」チャンクをトップN件(通常5〜20件)取得します。
⑧プロンプト拡張 — 取得したチャンクをユーザーの質問と組み合わせてプロンプトを構築します。「以下の参考情報に基づいて質問に回答してください。参考情報に記載のない内容は回答しないでください。」という指示とともに、関連チャンクをLLMに送信します。
⑨LLM回答生成 — LLMが、渡された参考情報を根拠にして回答を生成します。「就業規則第15条によると、入社1年後に12日間の有給休暇が付与されます」のように、出典を明示した回答が可能になります。
チャンキング — 文書をどう分割するか
チャンキングはRAGの精度を左右する最も重要な前処理工程です。チャンクが大きすぎると無関係な情報が混入して回答精度が下がり、小さすぎると文脈が失われて意味不明なチャンクになります。ここでは主要なチャンキング手法を整理します。
固定サイズチャンキング
最もシンプルな方法で、テキストを一定のトークン数(文字数)で機械的に区切ります。実装が容易で処理速度も速いため、最初のプロトタイプに適しています。
推奨パラメータ
固定サイズチャンキングを実装するときに、まず試すべき推奨パラメータは以下の通りです。
- チャンクサイズ — 300〜800トークン(日本語で約500〜1,300文字)
- オーバーラップ — チャンクサイズの10〜20%(前のチャンクの末尾と次のチャンクの先頭を重複させる)
- オーバーラップの目的 — 文の途中で切れることを防ぎ、チャンク間の文脈をつなぐ
たとえば500トークンのチャンクサイズで10%のオーバーラップを設定すると、各チャンクの末尾50トークンが次のチャンクの先頭に重複します。これにより「この規定は前項に定める手続きに従い〜」のような、前のチャンクへの参照を含む文が途切れるリスクを軽減できます。
セマンティックチャンキング
テキストの「意味の切れ目」を検出して分割する高度な手法です。見出し・段落の構造、話題の転換点などを分析し、意味的にまとまりのある単位でチャンクを作成します。
法的文書や技術文書のように構造が明確な文書で特に効果的です。ある研究では、法的文書に対するセマンティックチャンキングが、固定サイズチャンキングと比較してF1スコアを36%改善したという報告があります。
ただし実装の複雑さが増し、処理速度も低下するため、文書の種類と求める精度に応じて判断する必要があります。
Small-to-Big戦略
検索用とLLMへの提供用で異なるサイズのチャンクを使い分ける手法です。小さなチャンク(150〜300トークン)でインデックスを作成し、ヒットしたチャンクの前後の文脈を含む大きなチャンク(1,000〜2,000トークン)をLLMに渡します。
なぜSmall-to-Bigが効果的なのか
小さなチャンクは検索の精度が高くなります。「有給休暇の付与日数」というピンポイントの質問に対して、500トークンのチャンクより150トークンのチャンクのほうが、ノイズの少ない検索結果を返すからです。一方、LLMが回答を生成するには周辺の文脈も必要なので、ヒットしたチャンクを含む大きなブロックを渡します。
RecursiveCharacterTextSplitter(デフォルト推奨)
LangChainなどのフレームワークで標準的に使われるチャンキング手法です。段落→文→単語の順に、階層的にテキストを分割します。まず段落単位で分割を試み、チャンクサイズを超える場合は文単位、それでも超える場合は単語単位に分割します。
「まず何を使えばいいかわからない」という場合は、RecursiveCharacterTextSplitterをチャンクサイズ500トークン・オーバーラップ50トークンで設定するのが安全なスタートラインです。
| チャンキング手法 | 精度 | 実装難易度 | 適した文書 |
|---|---|---|---|
| 固定サイズ | △ 標準 | ◎ 簡単 | 構造が均一なテキスト |
| セマンティック | ◎ 高い | △ 難しい | 法的文書・技術仕様書 |
| Small-to-Big | ◎ 高い | ○ 中程度 | 長文ドキュメント全般 |
| Recursive | ○ やや高い | ◎ 簡単 | 汎用(迷ったらこれ) |
エンベディング — テキストをベクトルに変換する仕組み
エンベディング(Embedding)とは、テキストを数値のベクトル(配列)に変換する技術です。RAGの検索精度はエンベディングモデルの性能に大きく依存するため、適切なモデルの選択が重要になります。
ベクトルとは何か — 「意味の座標」
ベクトルとは、テキストの「意味」を多次元の数値空間上の点として表したものです。よく引用される有名な例として、「王」−「男」+「女」=「女王」という計算があります。
これは、「王」のベクトルから「男性性」を表す方向を引き、「女性性」を表す方向を足すと、「女王」のベクトルに近い位置にたどり着くことを意味しています。つまりエンベディングモデルは、単語や文章の意味的な関係性を数学的な構造として捉えているのです。
この性質のおかげで、「有給休暇の日数を教えて」と「年次休暇は何日もらえますか?」という、表現は異なるが意味は同じ2つの質問が、ベクトル空間上で近い位置に配置されます。これがRAGの「意味で検索する」を実現する核心技術です。
主要エンベディングモデルの比較
2026年時点で実務に使える主要なエンベディングモデルを比較します。
| モデル | 提供元 | 最大次元数 | 特徴 |
|---|---|---|---|
| text-embedding-3-large | OpenAI | 3,072 | 高精度・次元削減対応(256次元まで圧縮可能) |
| embed-v4 | Cohere | 1,024 | 多言語対応・検索特化の学習・ハイブリッド検索との相性良好 |
| voyage-3 | Voyage AI | 1,024 | コード検索に強い・Anthropic推奨 |
| BGE-M3 | BAAI(オープンソース) | 1,024 | 100言語以上対応・Dense+Sparse+ColBERTの3方式を1モデルでサポート |
次元数とコストのトレードオフ
エンベディングの次元数は、精度とコスト(ストレージ容量・検索速度)のトレードオフです。3,072次元のベクトルは高精度ですが、ストレージも検索コストも増加します。
OpenAIのtext-embedding-3-largeは「Matryoshka Representation Learning」という技術を採用しており、3,072次元のベクトルを256次元まで削減しても、実用上十分な精度を維持できます。100万件規模のドキュメントを扱う場合、256次元にすることでストレージコストを約12分の1に圧縮できるため、まず256次元で始めて精度に問題があれば次元数を上げるアプローチが現実的です。
エンベディング選びで失敗しないために
エンベディングモデルの選定は、後で変更すると再構築コストが大きいので慎重に行います。
- 検索対象の言語とエンベディングモデルの対応言語を確認する。英語特化のモデルで日本語文書を検索すると精度が大幅に低下する
- インデックス構築時と検索時で必ず同じモデルを使う。異なるモデルのベクトルは比較できない
- モデルを変更するとインデックスの再構築が必要になる。初期選定は慎重に行う
ベクトルデータベース — 類似度検索を支える基盤
ベクトルデータベース(Vector Database)は、エンベディングされたベクトルの保存と、高速な類似度検索に特化したデータベースです。通常のRDB(MySQL、PostgreSQL等)でもベクトル検索は可能ですが、数十万〜数億件規模になるとベクトルDBの性能差が顕著になります。
4大ベクトルデータベースの比較
| ベクトルDB | 提供形態 | 主な特徴 | 適した用途 |
|---|---|---|---|
| Pinecone | フルマネージド(クラウド) | ゼロオペレーション管理。サーバーレスプランでコスト効率が高い。メタデータフィルタリングが強力 | 運用負荷を最小化したいチーム。中小規模からエンタープライズまで |
| Weaviate | マネージド / セルフホスト | ハイブリッド検索(ベクトル+BM25)を標準搭載。GraphQL APIでクエリが柔軟 | ハイブリッド検索を重視するプロジェクト。オンプレミス要件がある場合 |
| Milvus | オープンソース / クラウド(Zilliz) | 10億ベクトル規模の大規模データに対応。GPU高速化をサポート | 大規模なデータ基盤。画像・動画のマルチモーダル検索 |
| Qdrant | オープンソース / クラウド | Rust製で高速。豊富なメタデータフィルタ。ディスク上のインデックスでメモリ効率が良い | パフォーマンスとコストのバランス重視。セルフホストで細かく制御したい場合 |
選び方の判断基準
どのベクトルDBを選ぶべきか
プロジェクトの要件・規模・運用環境によって最適なベクトルDBは異なります。代表的な選び方の指針は次の通りです。
- 「まず動くものを作りたい」 — Pineconeのサーバーレスプラン。インフラ管理不要で、無料枠もある
- 「社内ネットワーク内で完結させたい」 — Qdrant または Weaviate のセルフホスト版。Docker一つで起動可能
- 「数億件のデータを扱う」 — Milvus。分散アーキテクチャで水平スケールに対応
- 「ベクトル検索とキーワード検索を両方使いたい」 — Weaviate。ハイブリッド検索が組み込み済み
なお、PostgreSQLの拡張機能「pgvector」を使えば、既存のPostgreSQLにベクトル検索機能を追加することもできます。数万件程度の小規模であれば、新たにベクトルDBを導入せずにpgvectorで十分なケースもあります。
検索精度を上げるテクニック
ベクトル検索だけでは取りこぼしが発生します。「年末調整」で検索したいのに、ベクトル空間上では「確定申告」に近い文書ばかりヒットしてしまう、というケースです。ここでは、検索精度を劇的に改善する2つのテクニックを解説します。
ハイブリッド検索 — ベクトル検索 × キーワード検索
ベクトル検索(意味の近さで検索)とBM25キーワード検索(単語の一致で検索)を組み合わせる手法です。ベクトル検索は「意味は似ているが表現が異なる」文書を見つけるのが得意ですが、固有名詞や型番のような「完全一致が重要な」検索には弱い面があります。
ベクトル検索とキーワード検索の得意・不得意
ベクトル検索とキーワード検索は得意領域が異なるため、ハイブリッド構成が有効な理由を理解するには両者の特性を押さえておく必要があります。
- ベクトル検索が得意 — 「社員の休暇制度について教えて」→「有給休暇規定」「特別休暇一覧」がヒット(表現は異なるが意味は近い)
- ベクトル検索が苦手 — 「型番ABC-1234の仕様書」→ 関係のない製品の仕様書がヒットする場合がある
- キーワード検索(BM25)が得意 — 「ABC-1234」→ 完全一致で正確にヒット
- キーワード検索が苦手 — 「社員の休暇制度」→ 「有給休暇」「特別休暇」という単語が含まれない文書はヒットしない
両者を組み合わせるときに使われるのがRRF(Reciprocal Rank Fusion)というスコア統合手法です。ベクトル検索の順位とキーワード検索の順位を統合し、「両方の検索で上位に来る文書」をより高くランクします。
リランキング — 検索結果の再評価
ハイブリッド検索で取得したTop100件の候補を、より高精度なモデル(Cross-Encoder)で再評価し、本当に関連性の高いTop5〜10件に絞り込む手法です。
通常のベクトル検索は「Bi-Encoder」と呼ばれる方式で、質問とドキュメントを別々にベクトル化してからコサイン類似度を計算します。高速ですが、質問とドキュメントの細かな関係性を見落とすことがあります。
リランキングに使うCross-Encoderは、質問とドキュメントを一緒に入力して「この質問にこのドキュメントはどれくらい関連があるか」を直接スコアリングします。処理速度はBi-Encoderより遅いですが、精度は大幅に高くなります。全文書に適用すると遅すぎるため、「まずBi-Encoderで100件に絞り、Cross-Encoderで10件に絞る」という2段階パイプラインが定石です。
ハイブリッド検索 + リランキングの効果
実測データでは、ベクトル検索単体と比較して、ハイブリッド検索+リランキングの組み合わせで以下の改善が報告されています。特に社内ドキュメントのように専門用語や略語が多い環境では、この改善幅がさらに大きくなる傾向があります。
- Recall(取りこぼし防止) — 26%向上。関連文書を見逃す確率が大幅に低下
- Precision(ノイズ削減) — 28%向上。無関係な文書が検索結果に混入する確率が低下
RAGとファインチューニングの違い
「社内データをAIに活用する」方法として、RAGの他にファインチューニング(FT)があります。どちらを選ぶべきかは企業のAI導入における最も頻出の論点です。
比喩で理解する — 教科書持ち込み vs 猛勉強
2つのアプローチの本質的な違い
RAGとファインチューニングは「LLMをどう使うか」のアプローチが根本的に異なります。試験のメタファーで整理します。
- RAG(教科書持ち込み試験) — LLMの「脳」には手を加えない。代わりに「教科書」(外部データ)を渡して、それを見ながら回答させる。教科書を差し替えれば、明日から違う分野にも対応できる
- ファインチューニング(猛勉強して脳構造を変える) — LLMの「脳」(モデルの重み)そのものを、追加データで書き換える。特定分野に特化した「専門家の脳」を作る。ただし勉強し直す(再学習する)のに膨大な時間とコストがかかる
比較表
| 比較項目 | RAG | ファインチューニング |
|---|---|---|
| 初期コスト | 低い(ベクトルDB + エンベディング費用) | 高い(GPU計算リソース + データ整備) |
| データの鮮度 | リアルタイム更新可能 | 再学習が必要(数時間〜数日) |
| 実装難易度 | 中程度(既存フレームワークが豊富) | 高い(学習データの品質管理が難しい) |
| ハルシネーション | 抑制しやすい(出典を明示できる) | 抑制が難しい(学習データに混入すると永続化する) |
| 透明性・監査性 | 高い(参照元の文書を追跡できる) | 低い(モデル内部に埋め込まれるため追跡困難) |
| 推奨ケース | 社内文書検索、FAQ、カスタマーサポート | 特定の文体・トーンの生成、専門用語の理解向上 |
9割のユースケースはRAGで解決できる
企業が「社内データをAIに活用したい」と考えるとき、その要件の大半は「特定のドキュメントに基づいた正確な回答」です。これはまさにRAGの得意領域であり、ファインチューニングを持ち出す必要はありません。
ファインチューニングが有効なのは、LLMに「特定の口調で話させたい」「業界特有の略語をネイティブに理解させたい」といった、LLMの振る舞いそのものを変えたい場合に限られます。
ハイブリッド構成という選択肢
実際には「RAG or ファインチューニング」の二者択一ではなく、両方を組み合わせるハイブリッド構成も可能です。たとえば、ファインチューニングでLLMに業界用語の理解と適切なトーンを学習させた上で、RAGで最新のドキュメントを参照させるアプローチです。ただし、複雑さが増すため、まずはRAG単体で要件を満たせないかを検証してから検討するのが賢明です。
企業でのRAG活用シーン
RAGは「社内にある既存の文書やデータを、AIが参照できるようにする」技術です。業種や部門を問わず幅広い活用が可能ですが、特に効果が高い代表的なシーンを紹介します。
社内規約検索・FAQ自動回答
人事・総務部門の問い合わせ対応を自動化
就業規則、福利厚生制度、経費精算ルール、出張規定などの社内規約をRAGに登録することで、社員からの問い合わせにAIが即座に回答できます。「出張時のタクシー利用は申請が必要ですか?」という質問に対して、経費精算規定の該当条文を引用しながら正確に回答します。人事・総務への問い合わせ件数を大幅に削減でき、回答の属人化も防げます。
カスタマーサポートチャットボット
製品マニュアル、過去の問い合わせ履歴、トラブルシューティングガイドをRAGに登録し、顧客からの問い合わせに対してAIが一次対応を行います。従来のチャットボットは事前に設定したQ&Aパターンにしか対応できませんでしたが、RAGを組み合わせることで「マニュアルのどこかに書いてある」レベルの質問にも柔軟に対応可能です。
製造業の設計書・仕様書検索
製造業では、過去数十年にわたる設計書、仕様書、品質管理記録が蓄積されています。これらをRAGで検索可能にすることで、「過去に同様の不具合が発生した事例はあるか」「この部品の耐熱温度の仕様は」といった質問に、膨大な技術文書の中から瞬時に回答できます。ベテラン技術者の退職による知識の断絶を防ぐ効果もあります。
営業向けナレッジベース
製品情報、価格表、競合比較資料、過去の提案書、成功事例をRAGに登録すれば、営業担当者が商談準備に必要な情報を即座に取得できます。「A社向けに過去にどんな提案をしたか」「競合B社との機能比較」など、通常であれば社内の複数人に確認が必要な情報を、AIが横断的に検索して整理してくれます。
kintone × RAGの活用例
kintoneのデータをRAGで活用する
kintoneに蓄積された顧客対応履歴、案件管理データ、日報などのレコードをRAGのナレッジソースとして活用できます。たとえば、kintoneの「顧客対応履歴アプリ」のデータをエンベディングしてベクトルDBに登録すれば、「過去にX社から同様のクレームがあったか」「この製品で報告されている不具合の傾向」といった、kintoneの標準検索では難しい横断的な検索が可能になります。
RAGを導入する際の注意点
RAGは万能ではありません。導入にあたって見落としがちな5つの注意点を整理します。
知識ソースのデータ品質が最重要
RAGの回答精度は、入力するドキュメントの品質に直結します。「Garbage In, Garbage Out(ゴミを入れればゴミが出る)」の原則はRAGにも当てはまります。
データ品質でよくある問題
RAG導入の現場で頻発する、データ品質起因の典型的なトラブルパターンを整理しました。
- 古い版の社内規定が更新されずに残っている → 現行ルールと異なる回答が生成される
- PDFからのテキスト抽出が不完全で、表やグラフの情報が欠落している
- 同じ内容の文書が複数バージョン存在し、どれが最新か判別できない
- スキャンPDFで文字が画像として保存されており、テキスト抽出ができない
RAGの導入プロジェクトでは、技術的な実装よりも「どのドキュメントを、どのように整理してインデックスに登録するか」というデータ準備に全体工数の60〜70%を費やすことが一般的です。
セキュリティとアクセス制御
社内文書には機密情報が含まれます。RAGに登録する際は、「誰がどの文書にアクセスできるか」を適切に管理する必要があります。全社員が役員会議の議事録にアクセスできてしまう、といった事態を防ぐため、既存の文書管理のアクセス権限をRAGにも反映させる仕組みが必要です。
具体的には、チャンクにメタデータ(部署、機密レベル等)を付与し、検索時にユーザーの権限に応じてフィルタリングする方式が一般的です。ベクトルDBのメタデータフィルタ機能を活用すれば、この制御を効率的に実現できます。
チャンクサイズと検索精度のバランス
セクション4で解説した通り、チャンクサイズの設定はRAGの精度に大きく影響します。しかし「最適なチャンクサイズ」は文書の種類や質問の性質によって異なるため、一律の正解はありません。小規模なテストデータで複数のチャンクサイズを試し、検索精度を評価してから本番に適用するアプローチが推奨されます。
定期的なデータ更新の仕組み
社内文書は日々更新されます。RAGのインデックスが古いままでは、「最新の就業規則では在宅勤務が週3日まで認められています」と回答すべきところを、旧版の規定に基づいた誤った回答を返す可能性があります。
ドキュメントの更新を検知し、該当チャンクのエンベディングを自動的に再計算する仕組み(データパイプライン)を構築しておくことが重要です。手動更新では遅かれ早かれ同期がずれます。
評価とモニタリング
RAGを導入した後も、回答品質を継続的に評価する体制が必要です。ユーザーからのフィードバック(「この回答は正しかった/間違っていた」)を収集し、検索精度やLLMの回答精度を定期的にモニタリングすることで、継続的な改善サイクルを回せます。
2026年の最新動向 — Agentic RAG・Graph RAG
RAGの技術は急速に進化しています。2026年時点で注目されている最新アプローチを紹介します。
Agentic RAG — 「いつ検索するか」をAIが自分で判断する
従来のRAGは「ユーザーの質問が来たら必ず検索する」という固定的なフローでした。Agentic RAGでは、AIエージェントが「この質問には検索が必要か」を自分で判断します。
たとえば「1+1は?」のような質問には検索は不要ですが、「当社の今期の売上目標は?」という質問には社内文書の検索が必要です。Agentic RAGでは、AIエージェントが質問を分析し、検索が必要な場合のみベクトルDBにアクセスします。さらに「最初の検索結果では情報が不十分だった」と判断すれば、クエリを書き換えて再検索することもできます。
Agentic RAGのイメージ
図書館の司書に例えると、従来のRAGは「どんな質問が来ても必ず書庫に行って本を探す」司書でした。Agentic RAGは「この質問は一般常識で答えられるな」「この質問は専門書を2冊確認する必要があるな」と判断できる熟練の司書です。無駄な検索を省き、必要な検索を漏れなく行うことで、回答の速度と精度が向上します。
Graph RAG — ナレッジグラフとベクトルDBの融合
Graph RAGは、文書間の関係性(リレーション)を活用する手法です。通常のRAGは個々のチャンクを独立に検索しますが、Graph RAGでは「AさんはB部門に所属」「B部門はCプロジェクトを担当」「CプロジェクトはD製品に関連」というように、エンティティ間の関係性をグラフ構造で保持します。
これにより、「Cプロジェクトに関わっている人は誰か」という質問に対して、直接的にはCプロジェクトとは紐づいていないAさんの情報も、グラフのリレーションをたどることで取得できます。複雑な組織構造や、製品と部品の依存関係など、関係性が重要な情報に特に効果的です。
マルチモーダルRAG — 画像・PDFもベクトル化
テキストだけでなく、画像・図表・PDFのレイアウト情報もエンベディングして検索対象にする手法です。製造業の設計図、医療の画像診断レポート、建築の図面など、テキスト化が難しい情報を含むドキュメントでも、画像そのものをベクトル化して検索できるようになります。
ColPaliやColQwenといったモデルは、ドキュメントのページを画像として処理し、テキストとレイアウトの両方を考慮したベクトルを生成します。これにより「この表の3列目に書かれている値は」のような、従来のテキストベースRAGでは対応困難だった質問にも回答できるようになります。
長コンテキストウィンドウはRAGの代替になるか
Geminiの200万トークン超の超長コンテキストウィンドウや、GPT-5.5の100万トークンコンテキストを見て、「文書を全部プロンプトに入れればRAGは不要では?」と思う方もいるかもしれません。
長コンテキストがRAGを代替できない理由
「全文をプロンプトに入れればRAGはいらない」とはならない理由が複数あります。コスト・精度・レイテンシ・スケールの4軸で整理します。
- コスト — 100万トークンを毎回送信するAPI料金は、ベクトルDB検索で必要な5〜10チャンクだけ送信する場合の数十〜数百倍
- 精度 — 「干し草の山から針を探す」問題。コンテキストが長くなるほど、LLMは中間部分の情報を見落としやすくなる(Lost in the Middle問題)
- レイテンシ — 大量のトークンを処理するための応答時間が長くなる
- スケール — 企業の社内文書は数百万〜数千万ページに及ぶことがあり、コンテキストウィンドウにすべて収まる規模ではない
とはいえ、長コンテキストウィンドウとRAGは「どちらか一方」ではなく、組み合わせて使うのが最適解です。RAGで関連文書を抽出し、長コンテキストウィンドウにその周辺のコンテキストも含めて入力することで、精度とコストのバランスを取れます。
実践 — はてなベースではRAGをこう使っている
ここまでの理論を踏まえて、はてなベース株式会社で実際に運用しているRAGシステムの仕組みと効果をお伝えします。
毎日1時間かけてインデックスを自動更新
はてなベースでは、社内のすべてのプロジェクトファイル(設計書、仕様書、議事録、提案書、コードなど)を対象に、毎日1時間のインデックス更新プログラムを自動実行しています。
このプログラムが行っていることは、前のセクションで解説した「データ準備フェーズ」そのものです。新しく追加・更新されたファイルを検出し、チャンキング(文書を小さな塊に分割)→ エンベディング(テキストをベクトルに変換)→ ベクトルDB保存 という処理を毎日繰り返しています。
はてなベースのRAG環境
実際にはてなベースで稼働しているRAGシステムのスペックを公開します。
| 項目 | 内容 |
|---|---|
| インデックス対象 | 社内プロジェクト全体(全部門の文書・コード・資料) |
| ファイル数 | 60,410ファイル |
| チャンク数 | 679,733チャンク(1ファイルあたり平均11チャンク) |
| 更新頻度 | 毎日自動更新(差分のみ、約1時間) |
| エンベディングモデル | sentence-transformers/all-MiniLM-L6-v2(軽量で高速なオープンソースモデル) |
| ベクトルストア | ChromaDB(各メンバーのローカル環境に配置) |
| アクセス方法 | Claude Code(AIコーディングツール)から直接検索 |
全メンバーがClaude CodeからRAGにアクセスできる
このRAGシステムの最大のポイントは、チームの全員がClaude Code(ターミナルで動くAIコーディングツール)から社内RAGに直接アクセスできる環境を整えている点です。
従来であれば、「あのプロジェクトの設計書どこだっけ?」「freeeとの連携仕様ってどうなってたっけ?」と疑問が出るたびに、社内のファイルサーバーやSlackの過去ログを手作業で探し回る必要がありました。これが1人あたり1日30分〜1時間かかるケースも珍しくありません。
RAGを導入したことで、この作業が1回の検索コマンドで完了するようになりました。しかも、RAGの類似度検索(ベクトル検索)は「文書の意味」を理解して関連するものを見つけてくるため、キーワードが完全一致しなくても正確な結果が返ってきます。
RAG導入で変わったこと
RAG環境を整えてから、社内の働き方・AIの使い方が次のように変わりました。
- 「とりあえずそれっぽいものを持ってくる」がなくなった — ベクトル検索は意味の近さで検索するため、本当に一番関連性の高い文書がピンポイントで返ってくる
- 全員が過去の情報を一通り調べに行く必要がなくなった — 大量のチャンクの中から必要な情報を瞬時に取得できるため、情報探しの時間がほぼゼロに
- AIの回答品質が「一般論」から「自社固有の回答」に変わった — Claude Codeが社内文書を参照した上で回答するため、的外れな一般論が出なくなった
実際の検索結果
以下は、実際にRAG検索を実行した画面です。社内ナレッジベース全体から、質問に関連するドキュメントが類似度スコア(どれだけ意味が近いかを0〜100%で表した数値)付きで返ってきます。
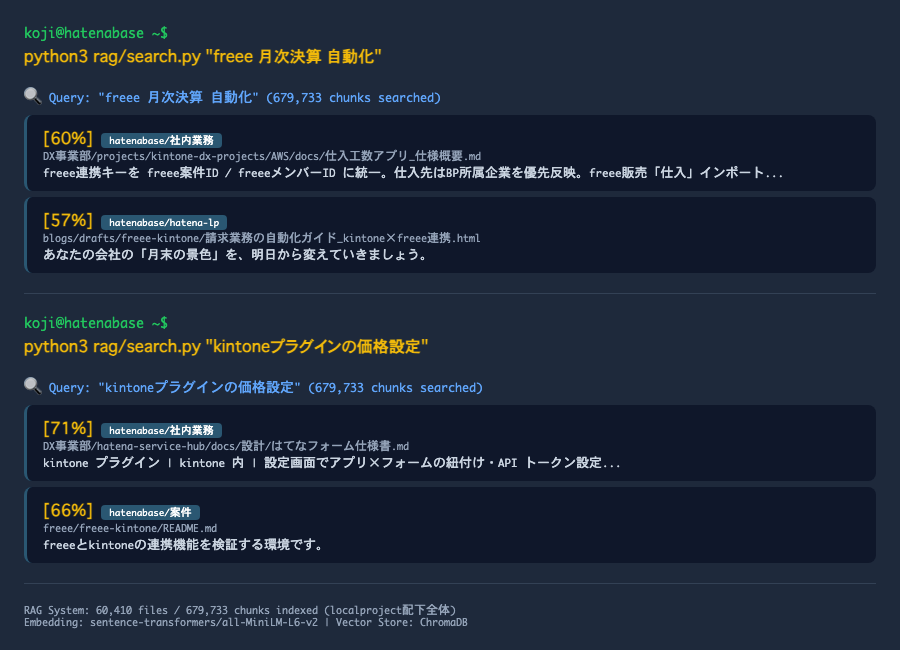
RAGなしとRAGありの回答品質の差
| 条件 | 質問「freeeの月次決算自動化について教えて」への回答 |
|---|---|
| RAGなし(素のAI) | freeeの一般的な機能説明が返る。「freeeでは自動仕訳ルールを設定できます」「月次レポートをエクスポートできます」など。自社の実装状況やkintone連携の詳細は一切含まれない。どの会社に聞いても同じ回答 |
| RAGあり(社内文書検索付き) | 社内の仕入工数アプリ仕様書やfreee-kintone連携の設計書が自動的に取得され、「freee案件IDとfreeeメンバーIDで連携キーを統一」「仕入先はBP所属企業を優先反映」など自社固有の実装詳細が回答に含まれる |
前の記事との接続
別の記事「生成AIがイケてないと感じる本当の原因」で、AIが的外れな回答を返す根本原因は「コンテキスト(文脈情報)が渡っていないから」だと述べました。RAGはまさにこの問題を仕組みとして解決するものです。AIに渡すコンテキストを「毎回手動でコピペ」するのではなく、「自動的に検索して渡す」ようにしたのがRAGの本質です。
まとめ
RAG(Retrieval-Augmented Generation)は、「AIに正しい情報を渡してから回答させる」というシンプルながら強力な仕組みです。LLMが学習していない自社データについて、ハルシネーションを抑制しながら正確に回答できるようになります。
この記事のポイント
ここまでの内容を6つのポイントに整理しました。
- RAGは「教科書持ち込みOKの試験」。LLMに外部データを参照させることで、自社固有の質問にも正確に回答できる
- 全体フローは「データ準備(チャンキング→エンベディング→ベクトルDB保存)」+「質問応答(検索→プロンプト拡張→LLM回答)」の2段階
- チャンキングは回答精度を最も左右する工程。迷ったらRecursiveCharacterTextSplitterから始める
- ハイブリッド検索(ベクトル+BM25)+ リランキングで、recall 26%・precision 28%向上が実証済み
- 9割のユースケースはファインチューニングよりRAGが適切
- 2026年はAgentic RAG・Graph RAG・マルチモーダルRAGなど、高度な手法も実用段階に
RAGの導入は、必ずしも大規模な開発プロジェクトを必要としません。まずは特定の文書群(社内FAQや製品マニュアル)をベクトルDBに登録し、シンプルな質問応答システムを構築するところから始められます。その上で、ハイブリッド検索やリランキングを段階的に追加していくのが、失敗リスクの少ないアプローチです。
生成AIの回答品質に課題を感じているなら、その原因の多くは「AIに適切なコンテキスト(情報)が渡されていない」ことにあります。RAGは、この「コンテキスト不足」を解決するための、2026年時点で最も実績のあるアプローチです。
社内データ × AI活用でお悩みではありませんか?
はてなベースでは、RAGをはじめとする最新のAI技術を活用し、企業のデータ活用を支援しています。AIエージェント組み込みサポート(経理DX事業部による、RAGを活用した社内チャットボットやFAQ自動回答システムの設計から実装まで)、データ基盤の整備(RAG導入の前提となるドキュメント整理・データ統合)、オンプレミスAI導入支援(社内データをクラウドに出したくない企業向けに、オンプレミス環境でのRAG基盤構築)の3つの軸でご支援します。