はじめに
SaaSビジネスにおいて、解約率(チャーンレート)の管理はLTV(顧客生涯価値)を左右する最重要指標のひとつです。多くの企業がログイン頻度や機能利用率、サポート問い合わせ件数といった行動指標をダッシュボードで監視していますが、「数字が下がったことに気づいたときにはすでに手遅れだった」という経験をお持ちの方も少なくないのではないでしょうか。
その背景には、観測できる行動データの裏に「見えない心理状態」が存在するという本質的な課題があります。ログイン頻度が週に3回あったとしても、その顧客が「満足して使い続けている」のか「惰性でログインしているだけ」なのかは、数値だけでは判別できません。
本記事では、ベイズ統計と隠れマルコフモデル(HMM)を組み合わせた手法を用いて、顧客の行動ログから「Engaged(積極的利用)」「At-Risk(リスク状態)」「Disengaged(離脱傾向)」という3つの隠れた心理状態を推定し、解約リスクを事前に可視化するアプローチを検証します。
データ統合プラットフォームに蓄積された行動ログを「ただ眺める」段階から、「統計モデルで解釈し、施策に接続する」段階へ進むための具体的な方法論を、シミュレーション結果とともにお伝えします。
データ統合の進展とSaaS解約率の課題
データ統合は進んだ、その先が見えない
近年、生成AIの活用を見据えたデータ統合の動きが加速しています。Salesforce Data Cloud、Snowflake、Databricksなどのプラットフォームを導入し、社内外に分散していたデータを一元管理する企業が増えてきました。CRMの顧客情報、プロダクトの利用ログ、マーケティングのキャンペーンデータ、サポートのチケット情報など、多種多様なデータソースが統合環境に集約されています。
しかし、「データを統合した後に何をすべきか」という段階で足踏みする企業が多いのも事実です。ダッシュボードで現状を可視化するところまでは到達しても、そのデータを使って具体的にどのような分析を行い、どのような施策に接続すべきかが明確になっていないケースが散見されます。
SaaS解約率の問題はなぜ解決しにくいのか
SaaSビジネスにおける解約率は、月次チャーンレートが1%改善するだけで年間の収益に大きな差が生まれる、きわめてインパクトの大きい指標です。しかし、この課題に対する従来のアプローチには構造的な限界があります。
- 事後的な検知 「ログイン頻度が50%低下したらアラート」という設定では、低下が起きてからの対応になる
- 個別指標の断片的な監視 ログイン頻度、機能利用率、サポート件数をバラバラに見ていても、顧客の「全体像」は掴めない
- 文脈の欠落 同じ行動パターンでも、顧客の置かれた状態によって意味が異なることを考慮できない
統計的手法で「データと施策」のギャップを埋める
このギャップを埋めるために有効なのが、確率モデルに基づく統計的アプローチです。データ統合プラットフォームに蓄積された行動ログを、隠れマルコフモデルのような確率モデルに入力することで、観測データの裏にある「顧客の心理状態」を推定し、将来の状態遷移を確率として予測できるようになります。
これにより、「ダッシュボードを見る」から「モデルが自動でリスクを検知し、施策を提案する」という運用フローに転換できます。以降のセクションでは、この手法の理論と検証結果を段階的にお伝えしていきます。
理論 隠れマルコフモデルとは何か
直感的な理解
隠れマルコフモデル(Hidden Markov Model, HMM)は、「直接は観測できない状態」と「観測できるデータ」の関係を確率的にモデル化する統計手法です。一見難しそうな名前ですが、考え方はシンプルです。
HMMとは、「お客様の行動データ(ログイン回数など)から、直接見えないお客様の心理状態(満足・不安・離脱気味)を推定する技術」です。健康診断の血液検査で「数値から体の状態を推定する」のと同じ発想です。
日常生活に例えると、天気と体調の関係に似ています。友人の体調(「元気」「だるそう」「体調不良」)を毎日電話で聞くことはできますが、友人の住む街の天気は直接見えません。しかし、「晴れの日は元気な確率が高い」「雨の日はだるそうな確率が高い」という傾向があれば、体調の報告から天気を逆推定できます。
SaaSの解約予測に当てはめると、次のようになります。
- Engaged(積極的利用) サービスに満足し、積極的に利用している状態
- At-Risk(リスク状態) 何らかの不満や疑問を抱えているが、まだ離脱には至っていない状態
- Disengaged(離脱傾向) サービスへの関心が大きく低下し、解約に向かいつつある状態
- 週あたりのログイン回数
- 週あたりの主要機能の利用回数
- 週あたりのサポート問い合わせ件数
- 週あたりのセッション滞在時間(分)
HMMは、これらの観測データの時系列パターンから、各時点で顧客がどの隠れ状態にいるかを確率的に推定します。さらに、状態間の遷移確率を学習することで、「Engaged状態の顧客が来週At-Riskに移る確率は11.8%」といった予測が可能になります。
モデルの3つの構成要素
HMMは、以下の3つの要素で定義されます。
1. 状態遷移確率(Transition Probability)
ある隠れ状態から別の隠れ状態に遷移する確率を表します。たとえば「今週Engagedだった顧客が、来週もEngagedである確率は85.0%」「At-Riskに移る確率は12.0%」のように定義されます。この確率は3×3の行列(遷移行列)として表現され、各行の合計が1になります。
2. 出力確率(Emission Probability)
各隠れ状態において、どのような観測データが生成されるかの確率分布です。たとえばEngaged状態のユーザーは「ログイン回数が平均18回」「セッション時間が平均45分」といった特徴を持ちます。本記事では正規分布(ガウス分布)を用いてモデル化しています。
3. 初期状態確率
最初の時点(観測開始時)に顧客がどの状態にいるかの確率分布です。
「ベイズ」を加える意味
通常のHMMでは、パラメータの点推定(もっともらしい一つの値を求める)を行います。一方、ベイズ隠れマルコフモデルでは、パラメータそのものに「事前分布」を設定し、データを観測した後の「事後分布」を推定します。
具体的には、状態遷移確率にディリクレ分布(Dirichlet Distribution)と呼ばれる事前分布を設定します。ディリクレ分布は「確率の確率分布」であり、「遷移確率はこのあたりの値をとりやすいだろう」という事前知識を表現できます。
- 少量データでの安定性 事前分布が正則化の役割を果たし、データが少ない場合でも極端な推定結果を避けられる
- 不確実性の定量化 「この顧客がAt-Riskである確率は72%」のように、推定の確信度を数値化できる
- ドメイン知識の組込み 「一気にEngagedからDisengagedに移ることは稀だ」といったビジネス知識を事前分布として反映できる
実験 ダミーデータの設計
理論の有効性を検証するため、既知のパラメータでダミーデータ(シミュレーションデータ)を生成し、モデルがそのパラメータを正しく復元できるかを確認しました。実際の顧客データを使う前に、モデルの推定精度を担保するための重要なステップです。
データ設計の概要
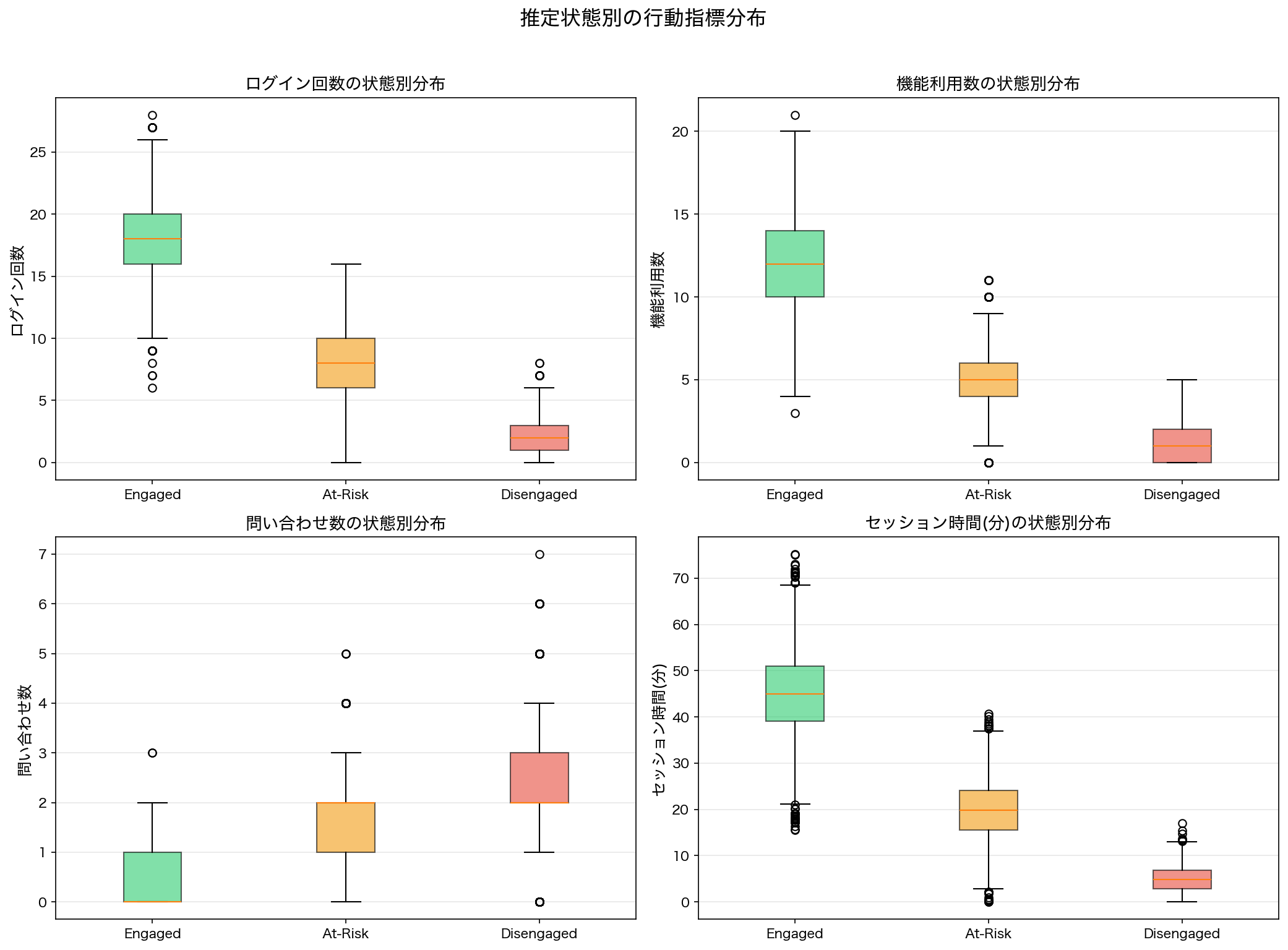
200人のSaaSユーザーについて、52週間(1年間)分の行動ログを生成しました。各ユーザーは毎週4つの指標が記録されます。
| 観測変数 | Engaged(平均) | At-Risk(平均) | Disengaged(平均) |
|---|---|---|---|
| ログイン回数/週 | 18.0 | 8.0 | 2.0 |
| 機能利用回数/週 | 12.0 | 5.0 | 1.0 |
| サポート問い合わせ件数/週 | 0.3 | 1.5 | 2.5 |
| セッション時間(分)/週 | 45.0 | 20.0 | 5.0 |
Engaged状態のユーザーは高頻度でログインし、長時間利用しており、サポートへの問い合わせは少ないという直感的に理解しやすいパターンになっています。反対にDisengaged状態のユーザーはほとんどログインせず、サポートへの問い合わせだけが多い(不満を感じている)傾向を示しています。
真の遷移行列
データ生成に使用した状態遷移確率(真の遷移行列)は以下の通りです。
| 遷移元 → 遷移先 | Engaged | At-Risk | Disengaged |
|---|---|---|---|
| Engaged | 0.850 | 0.120 | 0.030 |
| At-Risk | 0.150 | 0.700 | 0.150 |
| Disengaged | 0.050 | 0.180 | 0.770 |
この行列からは、いくつかの重要なビジネス上の意味が読み取れます。Engaged状態は比較的安定しており、85%の確率で翌週も維持されます。一方、At-Risk状態は不安定で、Engagedに回復する確率(15%)とDisengagedに悪化する確率(15%)が拮抗しています。Disengagedに一度陥ると、そこから脱出する確率は比較的低く(Engagedへ5%、At-Riskへ18%)、いわば「吸い込み状態」に近い性質を持っています。
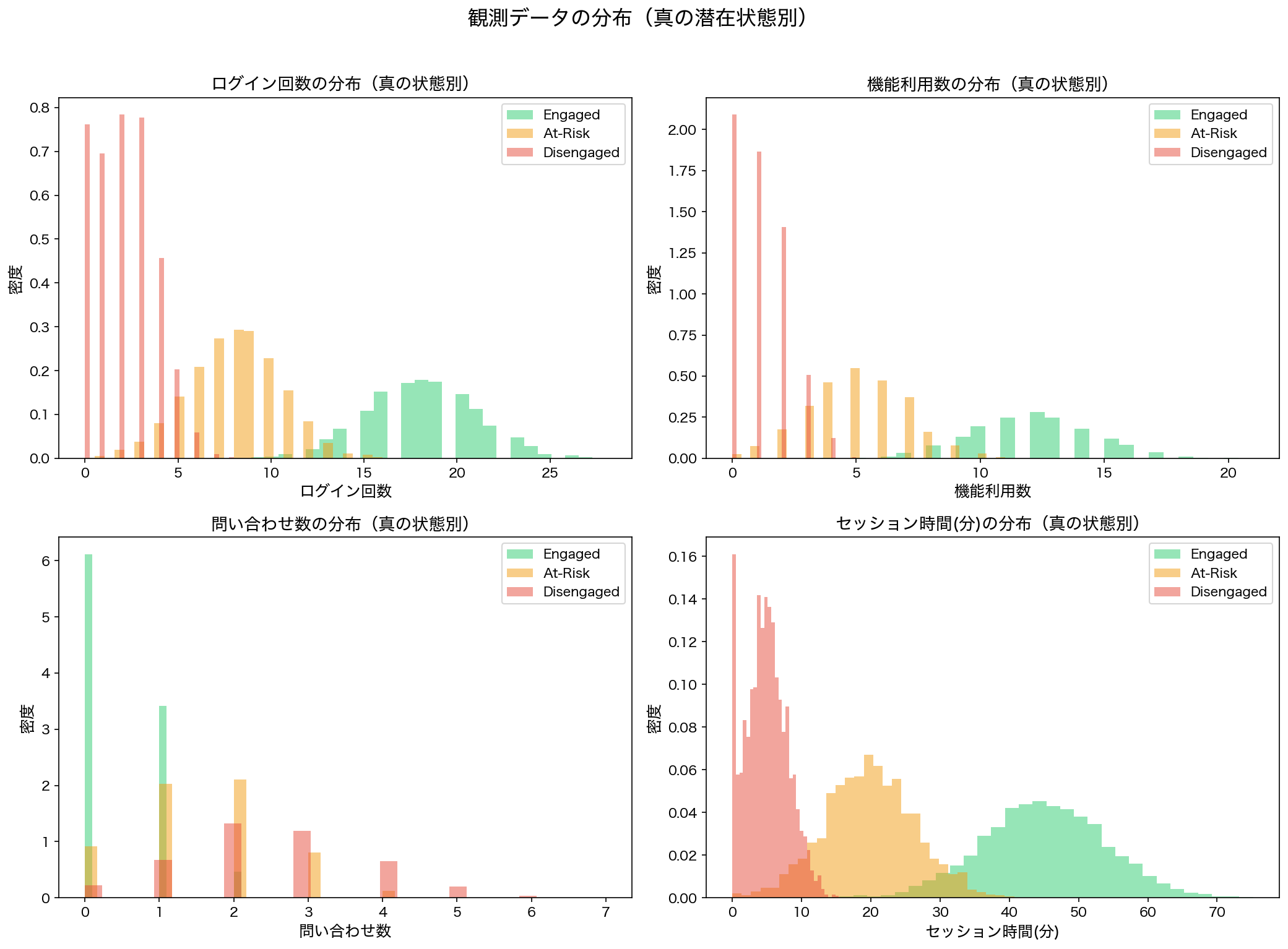
シミュレーションで生成した200ユーザー×52週間の行動データの概要。4つの観測変数の分布と状態別の特徴
モデルの学習と収束
ベイズHMMのパラメータ推定には、Baum-Welchアルゴリズム(EMアルゴリズムの一種)を使用しました。このアルゴリズムは、Forward-Backwardアルゴリズムで各時点の状態確率を計算し(Eステップ)、その結果に基づいてパラメータを更新する(Mステップ)というプロセスを収束するまで繰り返します。
今回の実験では、200ユーザー×52週間=10,400データポイントを入力として、モデルはわずか9回のイテレーションで対数尤度が収束しました。これは、データ量が十分であり、3状態モデルの設定が適切であったことを示しています。
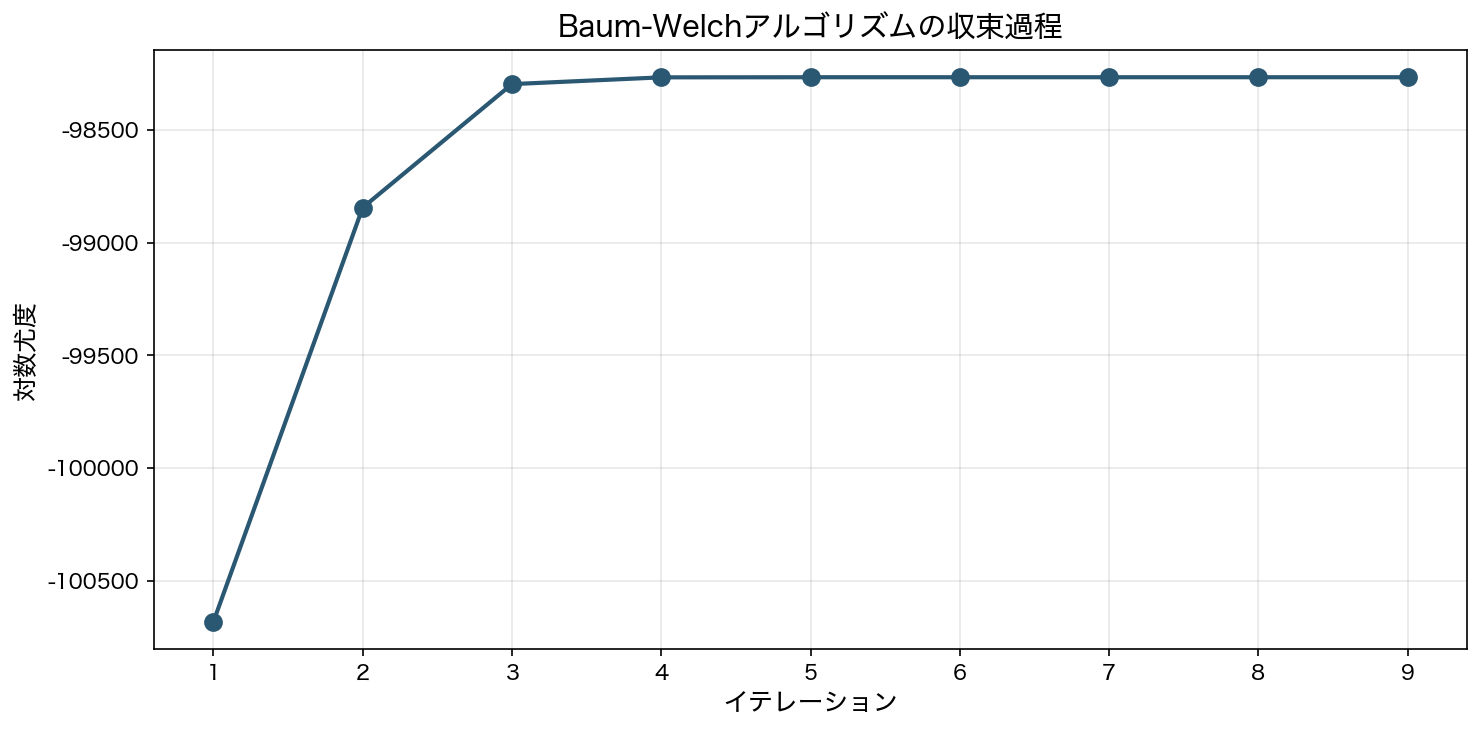
対数尤度の収束過程。9イテレーションで安定化しており、モデルが効率的に構造を発見できたことを示す
収束が速いということは、データに含まれる3つの状態のパターンが明確であり、モデルが効率的に構造を発見できたことを意味します。実データでは、状態間の境界がより曖昧になるため、イテレーション数は増える傾向にありますが、それでもデータ量が適切であれば安定した推定が可能です。
最終的に得られた推定パラメータを使い、ビタビアルゴリズム(Viterbi Algorithm)で各ユーザーの各週における最尤状態系列を復元しました。ビタビアルゴリズムは、観測データに対して最も確率の高い隠れ状態の系列を動的計画法で効率的に求める手法です。
推定結果の精度検証
推定された隠れ状態と、データ生成時に使用した真の隠れ状態を比較した結果、状態推定の精度は99.8%に達しました。10,400データポイントのうち、誤推定はわずか20ポイント前後に留まります。
パラメータの復元精度
出力分布の平均パラメータについて、真の値と推定値を比較します。
| 観測変数 | 状態 | 真の値 | 推定値 |
|---|---|---|---|
| ログイン回数 | Engaged | 18.0 | 18.1 |
| ログイン回数 | At-Risk | 8.0 | 8.0 |
| ログイン回数 | Disengaged | 2.0 | 2.1 |
| 機能利用回数 | Engaged | 12.0 | 12.0 |
| 機能利用回数 | At-Risk | 5.0 | 5.0 |
| 機能利用回数 | Disengaged | 1.0 | 1.1 |
| サポート問い合わせ | Engaged | 0.3 | 0.4 |
| サポート問い合わせ | At-Risk | 1.5 | 1.5 |
| サポート問い合わせ | Disengaged | 2.5 | 2.5 |
| セッション時間 | Engaged | 45.0 | 45.0 |
| セッション時間 | At-Risk | 20.0 | 19.8 |
| セッション時間 | Disengaged | 5.0 | 5.0 |
すべての変数において、推定値が真の値とほぼ一致していることがわかります。最大の誤差はセッション時間のAt-Risk状態で0.2分(真の値20.0に対して推定値19.8)であり、実用上まったく問題のない精度です。
遷移行列の復元精度
| 遷移パターン | 真の値 | 推定値 | 誤差 |
|---|---|---|---|
| Engaged → Engaged | 0.850 | 0.856 | +0.006 |
| Engaged → At-Risk | 0.120 | 0.118 | -0.002 |
| Engaged → Disengaged | 0.030 | 0.026 | -0.004 |
| At-Risk → Engaged | 0.150 | 0.149 | -0.001 |
| At-Risk → At-Risk | 0.700 | 0.706 | +0.006 |
| At-Risk → Disengaged | 0.150 | 0.144 | -0.006 |
| Disengaged → Engaged | 0.050 | 0.051 | +0.001 |
| Disengaged → At-Risk | 0.180 | 0.186 | +0.006 |
| Disengaged → Disengaged | 0.770 | 0.764 | -0.006 |
すべての遷移確率において、誤差は0.006以内に収まっています。モデルが状態間のダイナミクスを極めて正確に復元できていることが確認できました。
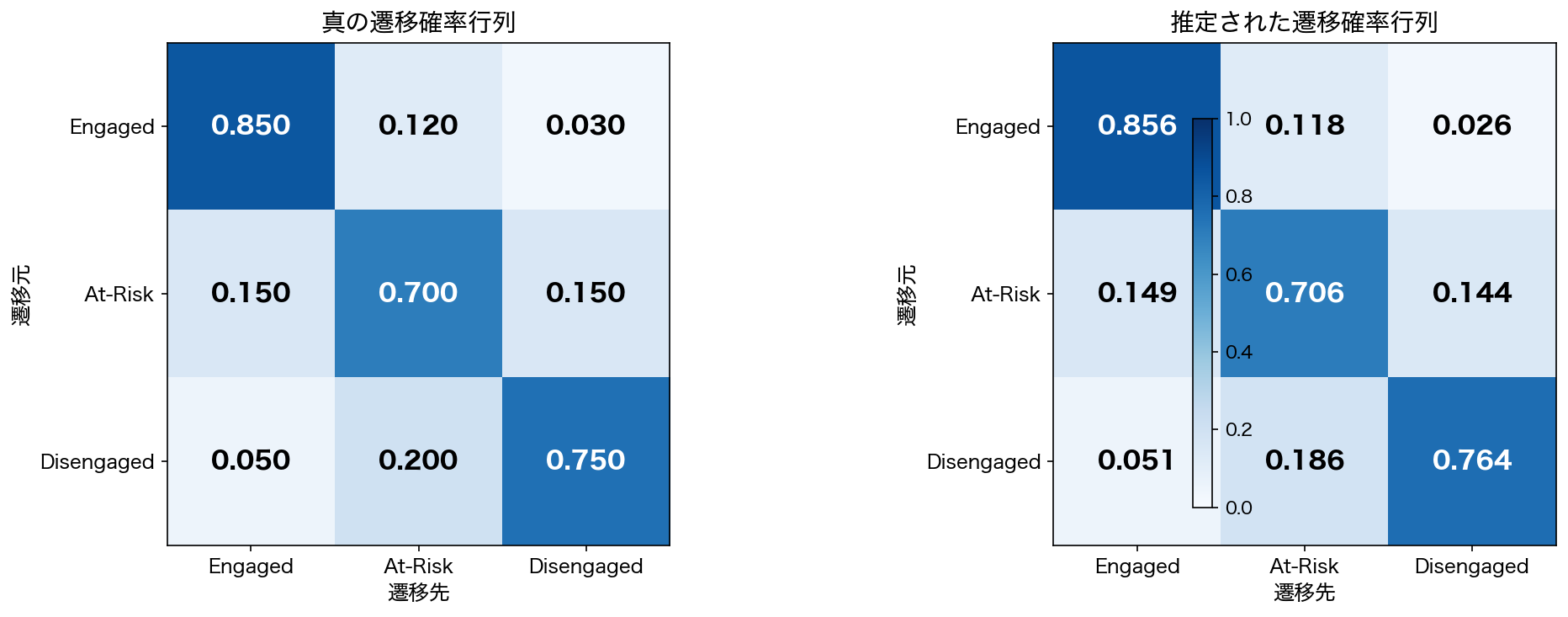
推定された状態遷移行列のヒートマップ。対角線上の値が大きく、各状態の安定性を示す
推定パラメータから得られるビジネスインサイトの要約
個別ユーザーの状態推移
モデルの有用性をより具体的に理解するため、個別ユーザーの状態推移を見てみましょう。以下の図は、あるユーザーの52週間にわたる行動データと、モデルが推定した隠れ状態の変化を示しています。
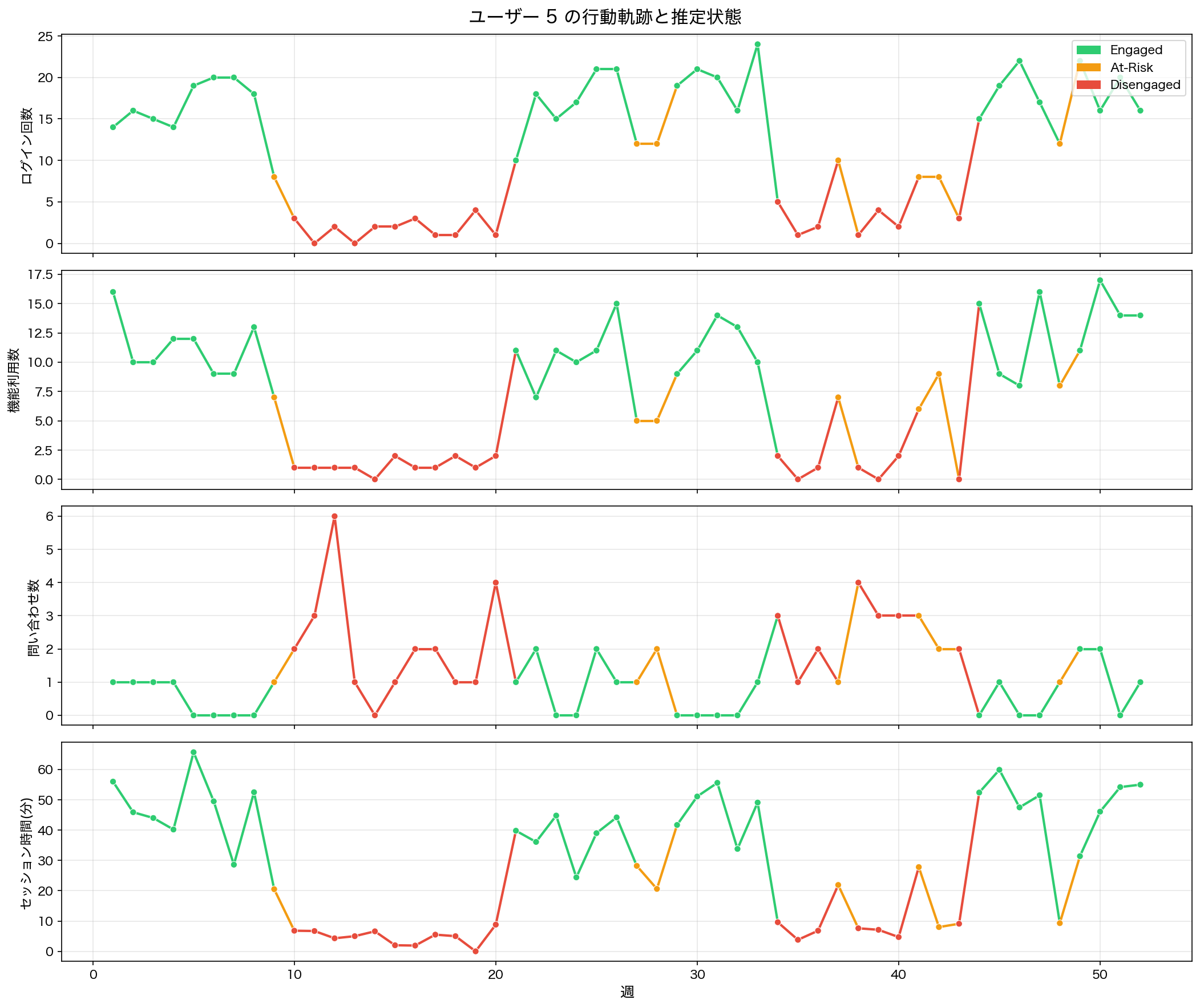
個別ユーザーの行動データと推定された隠れ状態の推移。行動指標の変化に連動して状態が遷移する様子が読み取れる
この図からは、行動指標の変化に先立って、あるいは連動して、隠れ状態が遷移していく様子が読み取れます。注目すべきは、ログイン回数や機能利用率が徐々に低下し始める「変曲点」で、モデルがEngagedからAt-Riskへの遷移を検知している点です。
単一の指標にしきい値を設けるアプローチでは、「ログイン回数が週10回を下回ったらアラート」のように定義するしかなく、グラデーション的な変化を捉えることが困難です。HMMは4つの観測変数を同時に考慮しながら、確率的に状態を推定するため、より繊細な変化を検知できます。
状態確率の時系列
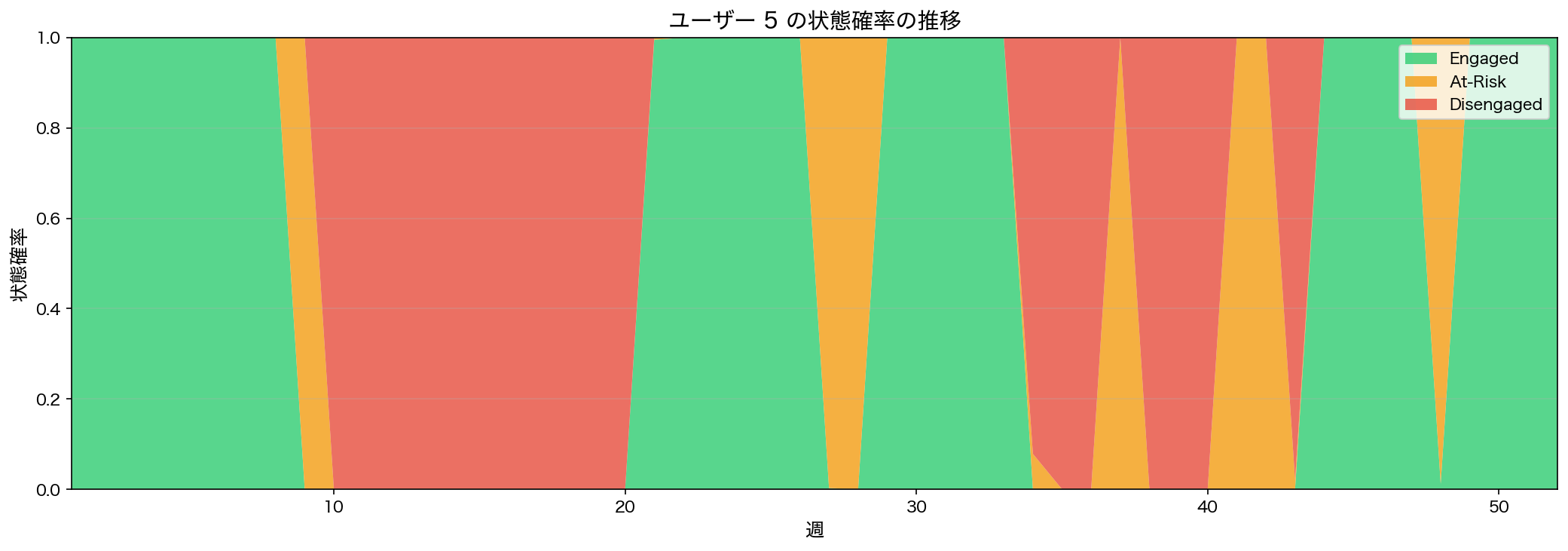
各時点における3つの隠れ状態に属する確率の推移。確率分布で状態を表現することで、介入の優先度を定量的に判断できる
上の図は、同じユーザーについて、各週で3つの状態それぞれに属する確率をプロットしたものです。ビタビアルゴリズムでは最も確率の高い状態を1つ選びますが、Forward-Backwardアルゴリズムを使えば、各時点の「確信度」を確率として出力できます。
「このユーザーは現在At-Risk状態です」という二値的な判定ではなく、「Engaged確率32%、At-Risk確率55%、Disengaged確率13%」のように確率分布を提示することで、介入の優先度を定量的に判断できます。たとえばAt-Risk確率が50%を超えたユーザーをカスタマーサクセスチームに自動でエスカレーションする、といった運用ルールを設計できます。
ユーザー基盤全体のヘルス
個別ユーザーの状態推移だけでなく、ユーザー基盤全体の「健全性」を俯瞰的に把握することも重要です。以下の図は、52週間にわたるユーザー基盤の状態構成比の推移を示しています。
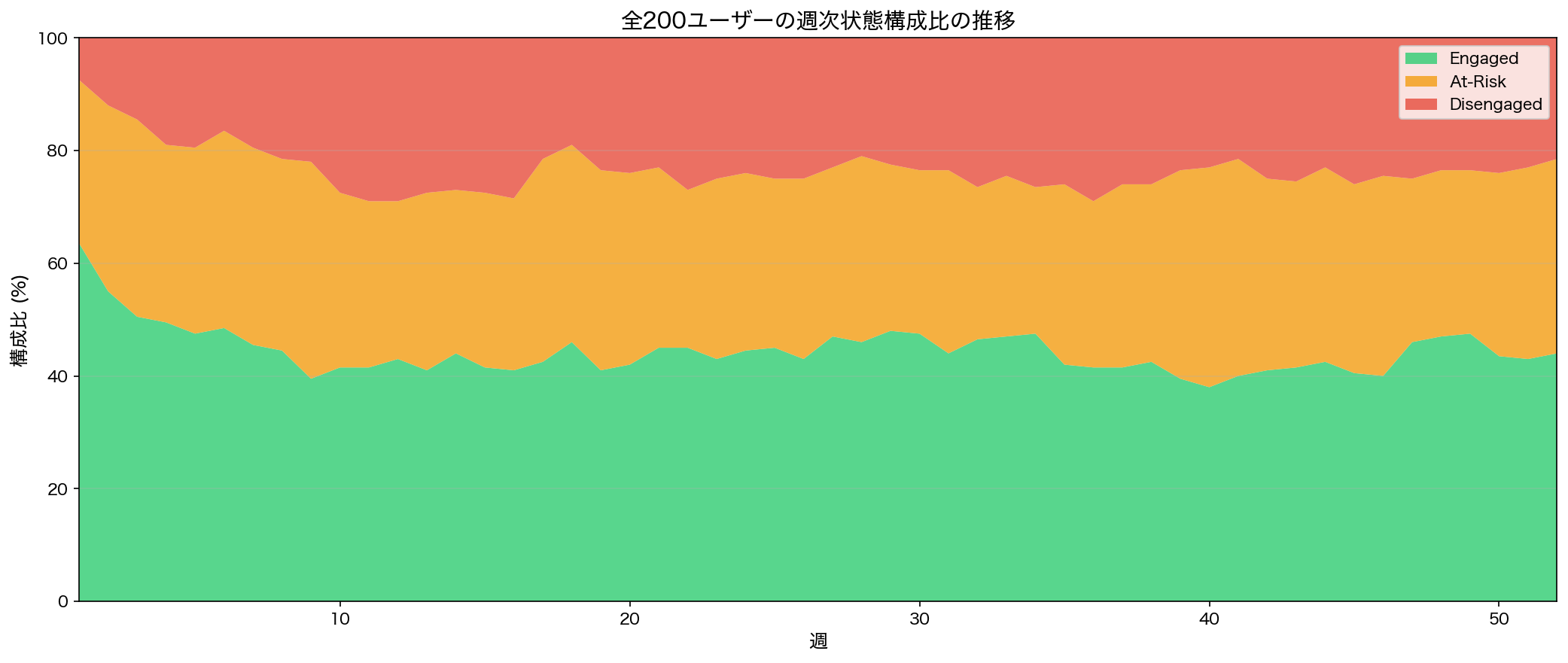
52週間にわたるユーザー基盤の状態構成比の推移。Engaged、At-Risk、Disengagedの比率変化がプロダクトの健全性を示す先行指標となる
この図は、経営層やマネージャーにとって非常に価値のある情報源になります。たとえば、以下のような判断に活用できます。
- トレンドの早期察知 Engaged比率が徐々に低下し、At-Risk比率が上昇しているトレンドがあれば、プロダクトや価格設定に構造的な問題がある可能性を示唆する
- 施策効果の検証 カスタマーサクセス施策を投入した時期の前後で、At-RiskからEngagedへの回復率が変化したかを確認できる
- 季節性の把握 年度末や四半期末に特定の状態遷移が集中するパターンを発見できる
従来のMRR(Monthly Recurring Revenue)やNRR(Net Revenue Retention)といったトップラインの指標は「結果」を示しますが、状態構成比は「原因」に近い先行指標として機能します。Disengaged比率の上昇は、数か月後のチャーン増加を予告するシグナルとなります。
ビジネスへの応用 チャーンリスクスコア
推定されたHMMのパラメータを活用して、各ユーザーに「チャーンリスクスコア」を付与することで、実際のビジネスオペレーションに接続できます。イメージとしては、顧客一人ひとりに「解約の危険度を0〜100で示す体温計」をつけるようなものです。
スコアの算出ロジック
チャーンリスクスコアは、各ユーザーの直近の状態確率と遷移行列を組み合わせて算出します。具体的には、直近時点のDisengaged確率に重みを置きつつ、At-Risk状態からDisengagedへの遷移確率も加味した複合的なスコアです。
チャーンリスクスコアの考え方
リスクスコア = Disengaged確率 × 0.5 + At-Risk確率 × Disengaged遷移確率 × 0.3 + 状態悪化トレンド × 0.2
このスコアに基づいて、200ユーザーを3つのリスクカテゴリに分類した結果は以下の通りです。
| リスクカテゴリ | ユーザー数 | 割合 | 推奨アクション |
|---|---|---|---|
| Low(低リスク) | 88 | 44% | アップセル・クロスセルの提案 |
| Medium(中リスク) | 69 | 34% | ヘルスチェックの実施・活用支援 |
| High(高リスク) | 43 | 22% | 即時のエスカレーション・経営層面談 |
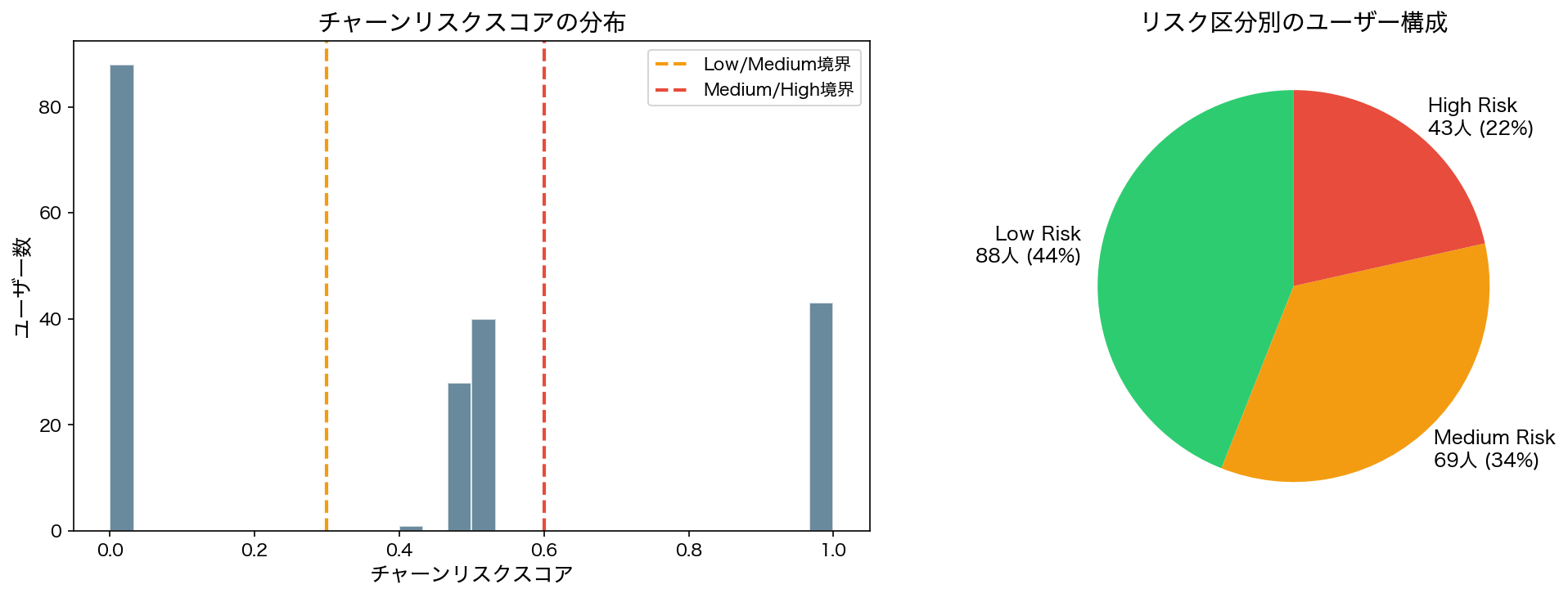
200ユーザーのチャーンリスクスコア分布。Low・Medium・Highの3カテゴリに分類し、それぞれに異なる介入アクションを割り当てる
しきい値ベースとの違い
- 時系列の文脈を考慮 単一時点のスナップショットではなく、過去の状態遷移パターンを反映したスコア
- 複数指標の同時評価 ログイン回数だけ、サポート件数だけ、といった個別判断ではなく、4変数を統合的に評価
- 確率的なグラデーション 「リスクあり/なし」の二値ではなく、連続的なスコアとして出力されるため、リソース配分の最適化が可能
- 将来の予測 遷移行列を用いることで、「現在At-Riskのユーザーが4週間後にDisengagedになる確率」を算出可能
介入戦略への接続
HMMの推定結果は、具体的な介入戦略の設計に直接活用できます。特に重要なのは、状態遷移のパターンごとに異なるアクションを定義することです。
遷移パターン別の介入アクション
| 遷移パターン | 確率 | 推奨アクション | タイミング |
|---|---|---|---|
| Engaged → At-Risk | 11.8% | プロアクティブなヘルスチェック連絡 | 遷移検知から1週間以内 |
| At-Risk → At-Risk(継続) | 70.6% | 活用事例の共有・トレーニング提案 | At-Risk状態が2週間継続時 |
| At-Risk → Disengaged | 14.4% | 経営層を含めたエスカレーション面談 | 遷移検知後すぐ |
| Disengaged → At-Risk(改善兆候) | 18.6% | 回復を後押しするサポートの強化 | 遷移検知のタイミング |
| At-Risk → Engaged(回復成功) | 14.9% | 回復要因の分析とナレッジ蓄積 | 回復確認後 |
At-Risk状態の「猶予期間」
推定された遷移行列から計算すると、At-Risk状態の平均滞在期間は約3.4週間です。つまり、「お客様が不安を感じ始めてから、完全に離脱するまでに約3週間の猶予がある」ということです。この3週間が、カスタマーサクセス担当者にとっての「勝負の期間」になります。
この3.4週間という数値は、カスタマーサクセスチームのオペレーション設計において非常に重要です。たとえば、週次でモデルを更新し、新たにAt-Riskに遷移したユーザーを自動で担当者にアサインするワークフローを構築すれば、理論上は2〜3週間の介入猶予を確保できます。
従来のしきい値ベースのアラートでは、「ログイン頻度が下がった」時点で初めて検知するため、実質的にはDisengagedに近い状態で発見されることが多く、介入が間に合わないケースが頻発していました。HMMを使えば、行動パターンの微細な変化からAt-Riskへの遷移を早期に検知できるため、介入のリードタイムを大幅に確保できます。
まとめ
本記事では、ベイズ隠れマルコフモデル(HMM)を用いて、SaaSユーザーの行動ログから「見えない心理状態」を推定し、解約リスクを事前に可視化するアプローチを検証しました。
- 200ユーザー×52週間のシミュレーションデータで、状態推定の精度は99.8%を達成
- 出力分布のパラメータ、遷移行列ともに真の値をほぼ正確に復元(最大誤差0.006以内)
- 9回のイテレーションで収束し、計算コストも実用的な範囲
- チャーンリスクスコアにより、Low 88人(44%)、Medium 69人(34%)、High 43人(22%)に分類
- At-Risk状態の平均滞在期間は約3.4週間で、介入の猶予期間として活用可能
データ統合プラットフォームの導入が進む今、「データを集めた後に何をすべきか」という問いに対するひとつの具体的な回答として、確率モデルによる顧客状態の推定は有力な選択肢です。単なるダッシュボード監視から一歩進み、「顧客の見えない心理状態を確率的に推定し、先回りで介入する」という運用フローへの転換は、SaaSビジネスの解約率改善に大きなインパクトをもたらします。
Salesforce Data Cloud、Snowflake、Databricksなどに蓄積された行動ログデータをお持ちであれば、本記事で紹介した手法は比較的短期間で検証が可能です。まずは自社のデータで小規模な検証を行い、モデルの有効性を確認するところから始めてみてはいかがでしょうか。
多くの企業が「データ統合」には投資したものの、その先の「分析」と「施策への接続」でつまずいています。はてなベースは、データ基盤の構築から、本記事で紹介したような高度な分析モデルの設計・実装、そして現場のカスタマーサクセスチームが日常的に使えるオペレーションへの落とし込みまで、一貫して支援しています。「データはあるが、使い方がわからない」という状態から抜け出すための最初の一歩を、ぜひご一緒させてください。