Claudeとは
Claudeは、AI安全性研究を専門とするAnthropic社が開発する大規模言語モデルです。OpenAIのChatGPTやGoogleのGeminiと並び、ビジネス向け生成AIの主要な選択肢として急速に存在感を高めています。
Anthropicは2021年にOpenAIの元メンバーが設立した企業で、「Constitutional AI」と呼ばれる独自の安全性手法を採用しています(Wikipedia – Anthropic)。Claudeという名前は、情報理論の父クロード・シャノンに由来しています(Wikipedia – Claude)。
2026年3月時点で、ClaudeはClaude 4.6世代とClaude 4.5世代の2世代が提供されています。4.6世代にはOpusとSonnetの2モデル、4.5世代にはHaikuが含まれ、合計3つのモデルから用途に応じて選べる構成です。
ChatGPT(OpenAI)が一般消費者向けの知名度で先行する一方、Claudeは長文処理能力や安全性の高さからエンタープライズ用途で支持を集めています。GeminiはGoogle Workspaceとの統合が強みですが、Claudeはコーディング支援やClaude Codeなどの開発者エコシステムで差別化を図っています。
3つのモデルの概要と特徴
Claudeのモデル一覧を見ると、Opus・Sonnet・Haikuの3モデルはそれぞれ異なるポジションを持っています。ここでは各モデルの特徴を整理します。
Opus 4.6 – 最高性能の頭脳
Opus 4.6はClaudeファミリーの最上位モデルです。複雑な推論を必要とするタスクや、長時間にわたるエージェントタスクで圧倒的な性能を発揮します。100万トークンのコンテキストウィンドウ(ベータ版)を備えており、大量の文書を一度に読み込んで分析できます。
- 高度な推論と分析が必要な業務に最適
- 長時間のエージェントタスクを自律的に遂行
- コーディング能力がモデル中最高水準
- 100万トークンコンテキスト(ベータ)で大量文書を一括処理
Sonnet 4.6 – バランス型の万能選手
Sonnet 4.6はClaude.aiでデフォルトに設定されているモデルです。Opusに迫る性能を持ちながら、コストは5分の1に抑えられています。SWE-bench VerifiedではOpusとの差がわずか1.2ポイントという僅差で、多くのビジネスユースでは十分な品質を提供します。
- 速度と品質のバランスに優れた標準モデル
- Opusの5分の1のコストで近い性能を実現
- 日常的な文書作成、要約、翻訳に最適
- チャットインターフェースのデフォルトモデル
Haiku 4.5 – 高速・低コストの実務派
Haiku 4.5は最もコンパクトなモデルで、処理速度の速さと低コストが最大の強みです。大量のテキストを分類・抽出する定型処理や、リアルタイムのカスタマーサポートなど、素早い応答が求められるシーンに適しています。
- 3モデル中最速の応答速度
- 大量処理やバッチ処理に最適なコスト効率
- テキスト分類、データ抽出、定型回答に強み
- APIコストを最小限に抑えたいケースに最適
ベンチマーク比較
AIモデルの性能を客観的に評価するため、主要なベンチマークスコアを比較します。これらのスコアはAnthropic公式サイトおよび各ベンチマーク運営元が公表しているデータに基づいています。
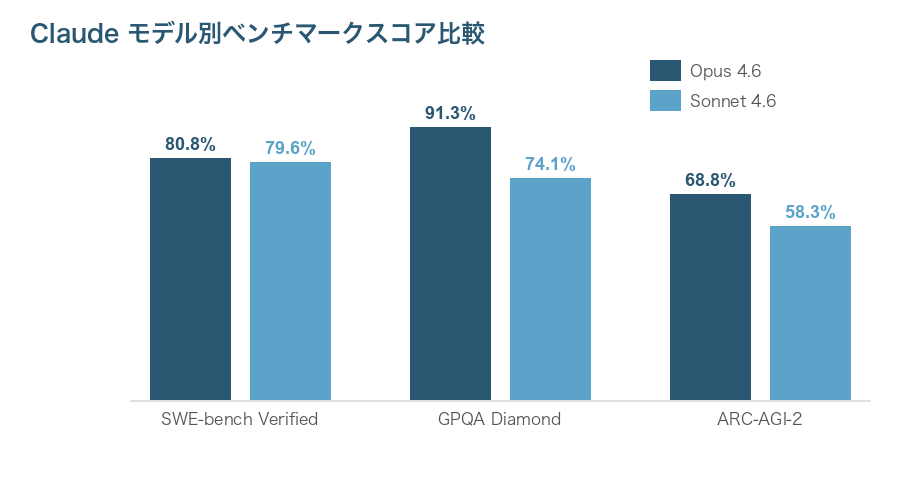
ベンチマークから読み取れること
SWE-bench Verifiedでは、OpusとSonnetの差はわずか1.2ポイントです。このベンチマークは実際のGitHubリポジトリのバグ修正を行う実践的なテストであり、日常的なコーディング支援であればSonnetでも十分な品質が得られることを示しています。
一方、GPQA Diamond(大学院レベルの専門知識を問うテスト)では17.2ポイントの大差がつきました。法務文書の精密な分析や、専門的な研究調査など、深い推論が求められるタスクではOpusの優位性が明確です。
ベンチマークスコアはモデルの「最大能力」を示すものであり、日常的な業務での体感品質とは必ずしも一致しません。たとえばメール文面の作成や議事録の要約といった一般的なタスクでは、3モデルとも十分な品質を発揮します。モデル間の差が顕著になるのは、複雑な推論や高度な専門知識を要するタスクに限られます。
料金比較
Anthropicの料金ページに記載されているAPI料金と、Claude.aiの個人プラン料金を整理します。
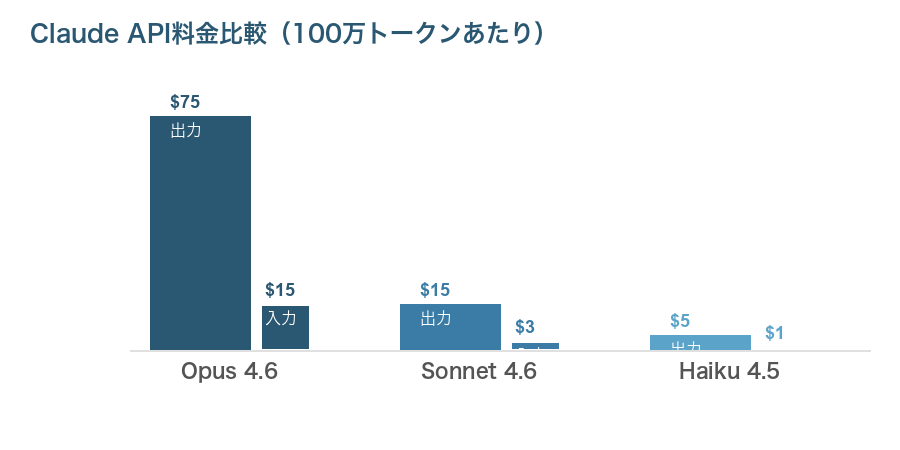
API料金(100万トークンあたり)
OpusとHaikuでは出力トークンのコストに15倍の差があります。1日に数百件の問い合わせを処理するカスタマーサポートのようなケースでは、この差が月間コストに大きく影響します。
Claude.ai プラン料金
コスト試算の具体例
たとえば、1件あたり平均500トークンの入力と1,000トークンの出力を想定した場合、1日100件処理すると月間のAPIコストは以下のようになります。
- Opus 4.6 … 入力 $22.5 + 出力 $225 = 約 $247.5/月
- Sonnet 4.6 … 入力 $4.5 + 出力 $45 = 約 $49.5/月
- Haiku 4.5 … 入力 $1.5 + 出力 $15 = 約 $16.5/月
同じ処理量でもモデルの選択だけで月額コストが約15倍変わります。すべてのタスクにOpusを使うのではなく、タスクの重要度に応じてモデルを使い分けることがコスト最適化の鍵です。
業務シーン別おすすめモデル
実際の業務でどのモデルを選ぶべきか、具体的なシーン別に整理しました。Anthropicのユースケース紹介も参考にしてください。
多くの企業では、1つのモデルに統一するのではなく、タスクの種類に応じて複数モデルを併用しています。たとえば日常業務はSonnet、重要な契約書のレビューだけOpusを使う、大量のデータ処理にはHaikuを回すといった運用で、品質を維持しながらコストを50%以上削減できた事例もあります。
モデル選択を誤ると、コストが膨らむだけでなく品質面でも問題が生じます。たとえば法務文書のチェックにHaikuを使うと、細かな条項の矛盾を見落とすリスクがあります。コスト削減だけを優先せず、タスクの重要度とリスクを考慮して選択してください。
モデル選びのポイントとまとめ
Claudeの3モデルは、それぞれ明確に異なるポジションを持っています。最後に、モデル選びで迷ったときの判断基準を整理します。
判断フローチャート
- 精度が最優先で、コストは二の次 → Opus 4.6
- 品質もコストもバランスよく → Sonnet 4.6
- 大量処理を低コストで回したい → Haiku 4.5
- まだ要件が固まっていない → まずSonnetで試し、必要に応じてOpusやHaikuに切り替え
まとめ
Claudeの3モデルは「松竹梅」のような単純な上下関係ではなく、それぞれに明確な強みがあります。Opusの圧倒的な推論力、Sonnetのコストパフォーマンス、Haikuの速度と低コスト。自社の業務に合ったモデルを選ぶことで、生成AIの導入効果を最大化できます。
迷った場合は、まずClaude.aiの無料プランでSonnetを試してみることをおすすめします。実際のタスクで使ってみれば、自社に必要な性能レベルが見えてくるはずです。より詳しいモデル仕様は公式ドキュメントで確認できます。