Excelの数式バーに =PY( と入力できるようになった──この一行の変化が、日常業務でのExcelの使い方を静かに変えつつあります。Microsoft 365 の Python in Excel は、セルの中でpandasやmatplotlibといったPythonのデータ分析ライブラリをそのまま呼び出せる機能で、2024年9月に一般提供が始まり、2026年現在はWindows・Mac・Webの三面で使えるようになりました。
本記事では、Python未経験〜初学者レベルの読者を想定して、Python in Excel が何者で、どう使えば業務に効くのかを一次情報をもとに整理します。ただ、あらかじめお伝えしておくと、この機能は「エンジニア向け」ではなく「分析をやりたいビジネス職向け」の設計思想で作られています。コードを書くというより、目的を言葉にしてAIにPythonを書いてもらい、自分は結果を読み取る──そんな関係性でも充分に価値が出ます。
Python in Excel の真価は、Pythonを"習得する"ことではなく、"Excelの限界を超える道具として呼び出す"ことにあります。関数で書けない集計・可視化・予測を、Copilotに自然言語で頼めば、中身のコードはAIが面倒を見てくれる──そういう関係性で使うのが、2026年時点の現実解です。
Python in Excel とは何か
Python in Excel は、Excelのセル内で直接Pythonコードを実行できる機能です。呼び出しには =PY( と打つだけで、セルが緑色のPython編集モードに変わり、そこに書いたコードがクラウド上で実行され、結果だけがワークシートに戻ってきます。pandas、NumPy、Matplotlib、seaborn、scikit-learn など、データ分析の定番ライブラリは最初から使える状態で入っており、追加インストールは不要です。
仕組みとして重要なのは、コードが実行されるのは利用者のPCではなく、Microsoft Azureのクラウド上のコンテナだという点です。具体的には、Anacondaが提供するPython環境がMicrosoftクラウドに常駐しており、ハイパーバイザーで他ユーザーから隔離された環境(=ハイパーバイザーで他ユーザーから隔離された環境)で演算が走ります。利用者のPCにPythonをインストールする必要はなく、社内ポリシーで追加ソフトが入れられない環境でも使えるのが実務上の大きな利点です。
リリースの変遷は次の通りです。2023年8月にパブリックプレビュー、2024年9月にWindows版GA、2024年10月23日に日本向けの正式アナウンス、2025年3月にExcel for the Web、2025年5月にMac版が続きました。2026年には、サイドパネルのコードエディターにIntelliSenseが加わり、Copilotによる自然言語→Pythonの自動生成が日本語を含む8言語に対応しています。
料金と利用条件
Python in Excel は、Microsoft 365 の主要プランに追加料金なしで同梱されています。契約さえしていれば、特別な購入プロセスは不要です。
| プラン | Python in Excel | 備考 |
|---|---|---|
| Microsoft 365 Personal / Family | ○ | 2025年3月以降。標準コンピュートのみ |
| Microsoft 365 Business Standard / Premium | ○ | 2024年9月GA。標準コンピュート込み |
| Office 365 E1 / E3 / E5 | ○ | E1は2025年6月以降 |
| Microsoft 365 Business Basic / F3 | ○(Web版のみ) | 2025年6月拡張 |
| Education A1 / A3 / A5 | Insider経由 | GCC High/DoDは非対応 |
| 永続ライセンス(Office 2021 / 2024) | × | サブスクのみ |
よく誤解されるのは「買い切り版Excel 2024 でも使えるのでは」という点ですが、これは対象外です。Python in Excel はサブスクリプション限定の機能で、買い切り版では利用できません。
高速処理が必要な部署には、Python in Excel add-on という月額24ドル/ユーザーのアドオンも用意されています。これを入れると手動・部分自動・自動の3つの計算モードが選択できるようになり、大規模データでの処理が安定します。ただしアクティベーションに24〜72時間かかるため、導入は余裕を持って。
使い方の基本フロー
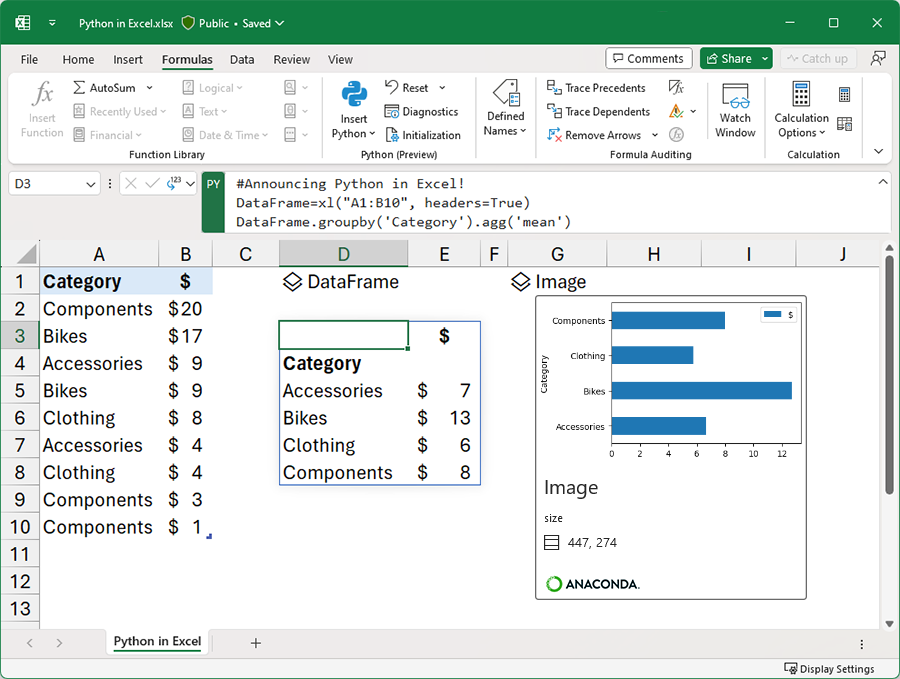
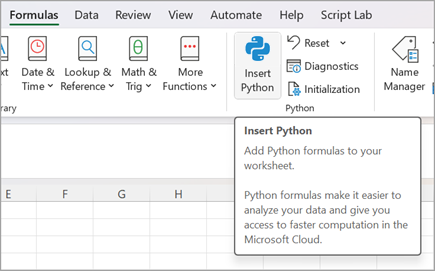
最初の一歩は拍子抜けするほどシンプルです。セルに =PY と入力するか、リボンの「数式」タブから「Pythonの挿入」を選ぶ。これでセルがPython編集モードに切り替わり、あとはコードを書いて Ctrl+Enter で確定するだけです。
ただ一点、Excelのセル範囲をPythonコードに渡す方法は最初に覚える必要があります。xl() という専用関数を使います。
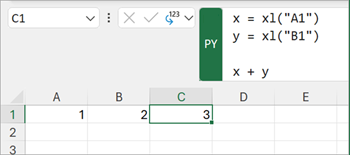
xl("A1") でセル値を取り出し、Python側で計算する(画像:Microsoft Support)df = xl("A1:D100", headers=True)
df.describe()この xl("A1:D100", headers=True) が「A1:D100の範囲を、1行目をヘッダーとして pandas DataFrame に変換する」という意味になります。Excelテーブル名を指定することもできて、xl("Sales[#All]", headers=True) のように書けば、テーブル全体を取り込めます。
結果の表示方法は2種類あります。既定の「Python Object」は、DataFrameをカード形式でセルに表示するモードで、Python側の操作を続けたいときに便利です。一方「Excel Value」に切り替えると、DataFrameの中身が普通のExcelセルとして展開され、その値に対して通常の数式やピボットテーブルが使えます。セルを右クリック→「Python出力」で切り替えられます。
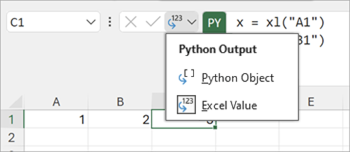
筆者の感覚では、ひとつの作業の中で両方を行き来するのが実用的です。Python Objectのまま分析を続けて、最後の最後に結果をExcel Valueに展開して他の人に共有する──こういう使い方が、Excelらしい「表で扱いたい」要求と噛み合います。
なお、計算順序は「行優先・左上から右下へ」です。つまりA1セルで作成したDataFrameをB1で参照するのはOKですが、A2セルで作ったものをA1で使うことはできません。Jupyterに慣れた人は混乱するポイントです。
実例10パターン(コード付き)
実務で使うパターンを10個、目的別に並べます。コピー&ペーストで動くよう、列名や範囲はサンプルで書いています。自分のデータに合わせて読み替えてください。
1. 基本統計量を一発で
データを渡すだけで、平均・標準偏差・四分位数がまとめて出ます。これだけでExcelのSUMやAVERAGEを10回書いていた作業が1行で終わります。
df = xl("Sales[#All]", headers=True)
df.describe()2. 重複除去とクレンジング
顧客マスタや注文データで必ず必要になる「重複削除と欠損値処理」は、pandasの得意分野です。
df = xl("Orders[#All]", headers=True)
df = df.drop_duplicates(subset=["OrderID"])
df["Amount"] = df["Amount"].fillna(df["Amount"].median())
df3. グループ集計(SQLのGROUP BY相当)
地域×商品ごとの売上合計、平均、件数をまとめて出します。
df = xl("Sales[#All]", headers=True)
df.groupby(["Region","Product"]).agg(
total=("Amount","sum"),
avg=("Amount","mean"),
count=("Amount","count")
).reset_index()4. 相関ヒートマップ
数十個ある指標間の相関を、色付きの表で可視化します。Excelのオートでは作れない領域です。
import seaborn as sns, matplotlib.pyplot as plt
df = xl("KPI[#All]", headers=True)
sns.heatmap(df.corr(numeric_only=True), annot=True, cmap="RdBu_r", center=0)
plt.show()5. 散布図+回帰直線
広告費と売上の関係を散布図で見て、回帰直線の式と決定係数(R²)を返します。
from scipy.stats import linregress
df = xl("Marketing[#All]", headers=True)
res = linregress(df["AdSpend"], df["Revenue"])
f"y = {res.slope:.1f}x + {res.intercept:.1f}, R²={res.rvalue**2:.3f}"6. K-meansで顧客クラスタリング
RFM(Recency・Frequency・Monetary)で顧客を4グループに分類します。マーケティングの初期分析の定番です。
from sklearn.cluster import KMeans
df = xl("Customers[#All]", headers=True)
km = KMeans(n_clusters=4, random_state=42, n_init=10)
df["Segment"] = km.fit_predict(df[["Recency","Frequency","Monetary"]])
df7. 時系列予測(指数平滑化)
月次売上の過去データから、次の半年を予測します。Facebook Prophetは同梱されていないので、statsmodelsの指数平滑化を使います。
from statsmodels.tsa.holtwinters import ExponentialSmoothing
df = xl("MonthlySales[#All]", headers=True)
df["Date"] = pd.to_datetime(df["Date"])
ts = df.set_index("Date")["Sales"]
fit = ExponentialSmoothing(ts, seasonal="add", seasonal_periods=12).fit()
fit.forecast(6)8. 異常値検知
平均±3σから外れた値を「異常」としてマークします。経理の月次仕訳チェックで効くパターンです。
df = xl("A1:D1000", headers=True)
mean, std = df["Amount"].mean(), df["Amount"].std()
df["is_outlier"] = (df["Amount"] - mean).abs() > 3 * std
df[df["is_outlier"]]9. テキストの正規表現置換
電話番号の表記ゆれを数字だけに統一する、といったクレンジングです。
df = xl("Contacts[#All]", headers=True)
df["電話番号"] = df["電話番号"].str.replace(r"[^d]", "", regex=True)
df10. 分類予測(ロジスティック回帰)
顧客の離脱(Churn)を予測するモデルを作って、確率を返します。Pythonに慣れていなくても、コード自体は短いので貼って動かせます。
from sklearn.linear_model import LogisticRegression
df = xl("Churn[#All]", headers=True)
X = df.drop("Churn", axis=1)
y = df["Churn"]
model = LogisticRegression(max_iter=1000).fit(X, y)
pred = model.predict_proba(X)[:,1]
pd.DataFrame({"ChurnProbability": pred})これらのコードは、Copilotに「顧客の離脱を予測するモデルを作って、確率を返して」と頼めばほぼ同じものを書いてくれます。Pythonを覚えずに使うルートも現実的です。
Copilotとの連携──"自然言語→Python"の時代へ
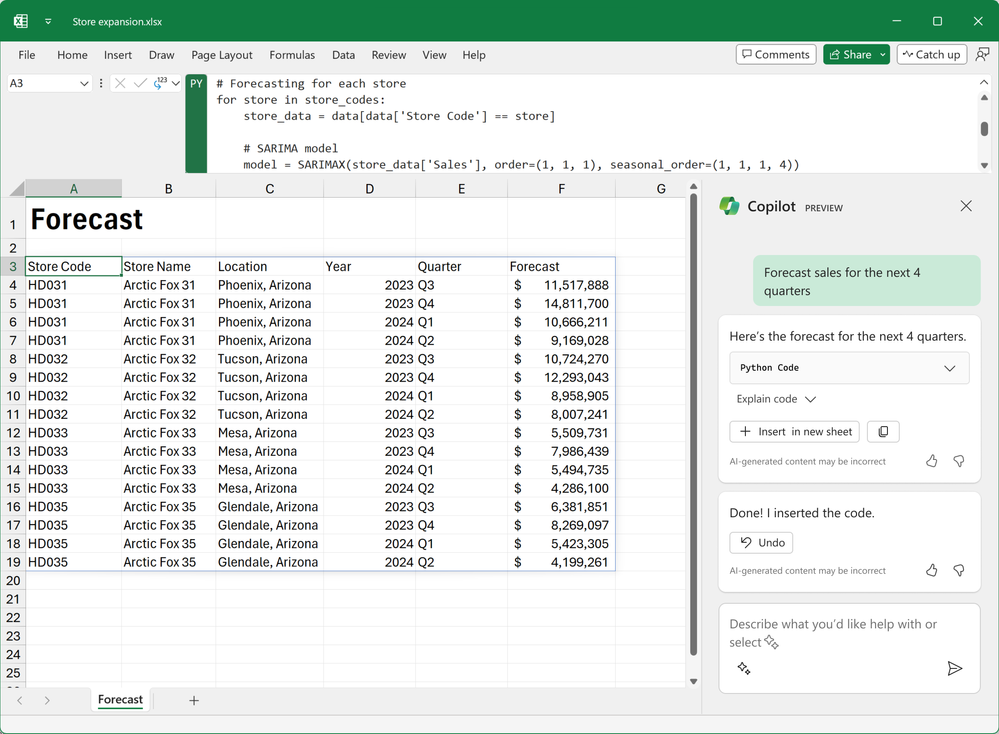
2026年時点での Python in Excel の最大の価値は、Copilotと組み合わせたときに発揮されます。「先月と今月の売上を比較するグラフを作って」と日本語で書くだけで、Copilotが =PY( ... ) のセルを自動で挿入し、中のPythonコードも書いてくれます。
対応する分析タイプは広く、予測、クラスタリング、最適化、因果推論、統計検定、分類、サンプリングなどが日本語プロンプトから指示できます。2026年時点で日本語を含む8言語が正式サポート対象です。
ただし条件があって、Microsoft 365 Copilotライセンスが別途必要です。Python in Excel 自体は追加料金なしで付きますが、Copilot連携だけは月額¥4,497/ユーザーのCopilotを契約している人に限られます。
実務観点では、Copilot抜きでもPython in Excelは使えます。ChatGPTやClaudeにコードを書いてもらって =PY() に貼り付けるだけ、でも充分機能します。Copilotはあくまで「Excelの中で完結させたいとき」の選択肢、と理解しておくと誤解がありません。
制限事項と落とし穴
便利な機能ほど、制約を知らずに使うと痛い目を見ます。Python in Excel で特に気をつけたい4点を挙げます。
1つ目は外部ライブラリのインストールが不可能なこと。Anacondaが厳選した約200のライブラリは使えますが、それ以外は追加できません。例えばFacebook ProphetやMeCab、GiNZAといった日本語形態素解析ライブラリは現時点で入っていないため、使いたい場合はAnaconda Codeアドインでローカル実行に切り替えるか、別の方法を探す必要があります。
2つ目は外部ネットワークへのアクセスが遮断されていること。セキュリティのため、Pythonコードから外部APIを叩いたり、Webスクレイピングしたり、社内DBに接続したりはできません。閉じた環境で完結する処理に限られる、と理解しておきましょう。
3つ目は計算順序の話で、先述したとおり「行優先・左上から右下」に固定されています。Jupyterに慣れていると感覚がずれやすいので、セル同士の依存関係を設計するときに意識してください。
4つ目はコンピュート制限。標準プランには月間コンピュート枠があり、これを超えるとエラー(#BLOCKED)が発生します。毎月1日にリセットされますが、重い処理を頻繁に走らせる部署は Premium Compute Add-on の契約を検討することになります。
また、モバイル版Excel(iPad/iPhone/Android)では Python in Excel は使えません。PC/Macで編集したファイルをモバイルで開くと、PY関数のセルはエラー表示になります。これは知らないとヒヤッとするポイントです。
セキュリティとガバナンス
企業導入で必ず聞かれる「社内データがPythonに渡って大丈夫か」という問いに、Microsoftは明確な回答を用意しています。
まず実行環境は、Microsoftクラウド上のハイパーバイザーで完全分離されたコンテナ(=ハイパーバイザーで完全分離されたコンテナ)です。そのコンテナは最小権限アカウントで動き、外向きネットワークは遮断されています。ワークブックを閉じるかタイムアウトするとコンテナは破棄され、クラウド側にデータは残りません。
準拠規格は GDPR、EUDB(EU Data Boundary)、HIPAA、HITRUST。EUの顧客は自動的にEUリージョンのコンテナで処理され、データはEU圏外に出ません。多国籍企業は Office Configuration Service で全コンテナを欧州化することもできます。
AI学習への利用については、Copilot経由の利用を含めてユーザーデータは学習に使われないとMicrosoftが明言しています。Microsoft Purview のDLP(情報漏洩防止)ポリシーも、通常のExcelワークブックと同じように適用されます。
社内展開にあたって情シス部門と詰めるべき論点は主に3つです。リージョンをどこに固定するか(EUDBを使うか)、管理者権限でPython in Excel をブロックする必要があるか(Windowsレジストリ経由で可能)、そして機密性ラベル付きワークブックでの挙動をどう扱うか。この3点を押さえれば、日本の大企業でも採用のハードルは高くありません。
他ツールとの住み分け
データ分析の選択肢はExcel+Pythonだけではありません。典型的な選択肢を並べると、それぞれの向き不向きが見えてきます。
| ツール | 実行場所 | 外部API | 非エンジニア向き |
|---|---|---|---|
| Python in Excel | Microsoftクラウド | 不可 | ◎(Copilot併用) |
| Anaconda Code(アドイン) | ローカルPC | 可 | △ |
| Jupyter Notebook | ローカル/サーバー | 可 | × |
| Google Sheets + Apps Script | Googleクラウド | 可 | △(JavaScript) |
| Power BI / Microsoft Fabric | ローカル/クラウド | 可 | △(運用向け) |
Python in Excel の立ち位置は「Excelから離れずに、分析の幅を広げたい人」向け。外部APIを叩いたり、PyPIから自由にパッケージを入れたい業務には Anaconda Code やローカルJupyterに分がありますし、本格的なBI運用は Fabric が優位です。万能ではないので、目的ごとに使い分けるのが現実解です。
とはいえ、日常業務で「ちょっと分析したい」のほとんどは、Python in Excel で済みます。使い分けというより、まずはPython in Excel から入って、壁にぶつかったら別の選択肢を検討する順序が、多くの職種で合理的です。
導入ステップと日本企業での使われ方
社内展開の進め方は、拍子抜けするくらい単純です。Microsoft 365 Business Standard 以上を契約している環境なら、ExcelのバージョンがWindows 2408以降、Mac 16.96以降になっていれば、今日から使えます。
まず1ブックで小さく試すのが第一歩です。=PY( を打って df.describe() を動かす、matplotlib で1つグラフを作る──この2つで、環境が使えるかどうかは即座に判定できます。動いたら、部門ごとに「毎月やっているExcel作業」のうち、関数やピボットで苦労している1つを選んでPython in Excel で置き換えてみる。これが定着までの最短ルートです。
日本企業での実例として挙がっているユースケースは、業界を問わず「分析の下地作り」と「既存のExcelジョブの置き換え」に集中しています。経理部門では月次試算表の外れ値検知や、勘定科目×部門のピボット超え集計。人事部門では従業員サーベイの集計や、勤怠データから残業偏りのクラスタリング。マーケティングや事業企画では顧客LTVの計算、広告費と売上の回帰分析、コホート分析、モンテカルロ・シミュレーションによる売上予測。いずれも以前はPython単独や専用ツールでやっていた仕事が、Excelの中で完結できるようになったという位置づけです。
管理職の立場で面白いのは、Copilot経由でPythonコードを読めないマネージャーでも、「先月の異常値を抽出して」と日本語で頼めば結果を受け取れる点です。自分でコードを書ける必要はなく、分析を指示する・結果を読む・次のアクションを決める、という本来やるべき仕事に集中できます。
逆に注意したいのは、Python in Excel をExcelの拡張機能として使うだけで満足すると、本格的な分析基盤への移行が遅れる点です。月次で数十万行のデータを扱うようになったり、外部APIからのデータ取り込みが必要になったら、Power BI / Fabric や Anaconda Code に移行する判断も視野に入れておくべきです。
最後に
Python in Excel は、「Pythonを覚えよう」という文脈ではなく、「Excelの限界を道具で拡張しよう」という文脈で読むと使いどころが見えてきます。pandas や matplotlib は覚えるに越したことはありませんが、Copilotに頼む前提で運用すれば、コードが書けなくても価値は充分に出ます。
まずは1つ、今週やっているExcel作業から「これPythonで楽になるんじゃないか」というものを選んで、試してみてください。追加費用なし、インストール不要、試行錯誤もすぐにやり直せる。導入のハードルとしては、現代のビジネスツールの中でも特に低い部類です。
Python in Excel の社内展開、はてなベースが伴走します
部門別のユースケース設計、テンプレート作成、CopilotとPython in Excelを組み合わせた研修カリキュラム、Anaconda Code など拡張ツールとの併用設計まで、経理DX事業部がご支援します。オンプレミスでのデータ分析基盤の構築もあわせて検討可能です。