この記事で検証すること
小売のクーポン施策を想定したダミーデータ(顧客5,000人・店舗30店・3ヶ月分)を生成し、「ただのA/Bテスト」で出た結論と、セグメント分解・利益ベース評価・ベイズ推定で出した結論がどれだけ異なるかを実際にプロットで示します。BIダッシュボードの棒グラフやLLMに聞いた要約では拾えない、意思決定に必要な分析とは何かを具体的に見ていきます。
A/Bテストが悪いわけではない。ただ、それだけでは足りない
小売のマーケティング施策を検証するとき、まず思い浮かぶのがA/Bテストです。ある施策を実施したグループと、実施していないグループを比較し、差が出たかどうかを見る。考え方としてはシンプルで、非常にわかりやすい方法です。
ただし、現実の小売の現場では、「ただのA/Bテスト」だけでは判断を誤る場面が少なくありません。
なぜなら、小売の施策効果は単純な二群比較では捉えきれないほど、さまざまな要因に影響されるからです。曜日、天候、季節性、競合のキャンペーン、店舗ごとの客層、顧客ごとの購買履歴、割引による粗利毀損、他商品の買い控え、短期効果と長期効果のズレ。こうした現実を無視してしまうと、A/Bテストの結果が出ていても、それをそのまま意思決定に使うのは危険です。
まず前提として、A/Bテストそのものを否定したいわけではありません。ランダム化によって比較可能な対照群を作るという考え方は、施策検証の基本です。実際、思いつきや単純集計だけで判断するより、A/Bテストを行う方がはるかに健全です。
問題なのは、A/Bテストをやったという事実だけで十分だと思ってしまうことです。
「A/Bテストで有意差が出たから成功」「差が出なかったから効果なし」。こうした結論の出し方は、小売の実務ではかなり危ういことがあります。
本記事では、実際にダミーデータを作って検証しながら、どこに落とし穴があるのかを具体的に見ていきます。
今回のシミュレーション設定
小売チェーンのクーポン施策を想定し、以下のダミーデータを生成しました。
- 顧客数 5,000人(新規30%、既存一般50%、既存優良20%)
- 店舗数 30店舗(施策群15店・対照群15店)
- 施策 150円クーポン配布(購入時に適用)
- 日次データ 90日分(曜日・天候・月末効果付き)
全体平均だけでは、誰に効いたかが分からない
小売施策の効果は、顧客全員に同じように出るわけではありません。たとえばクーポン施策ひとつ取っても、新規顧客には強く効く一方で、既存の優良顧客にはほとんど効かない、ということが普通に起こります。
ただのA/Bテストでは、しばしば全体平均の差だけを見て終わってしまいます。今回のダミーデータでも、全体の購買率だけを見ると明確な差が出ています。
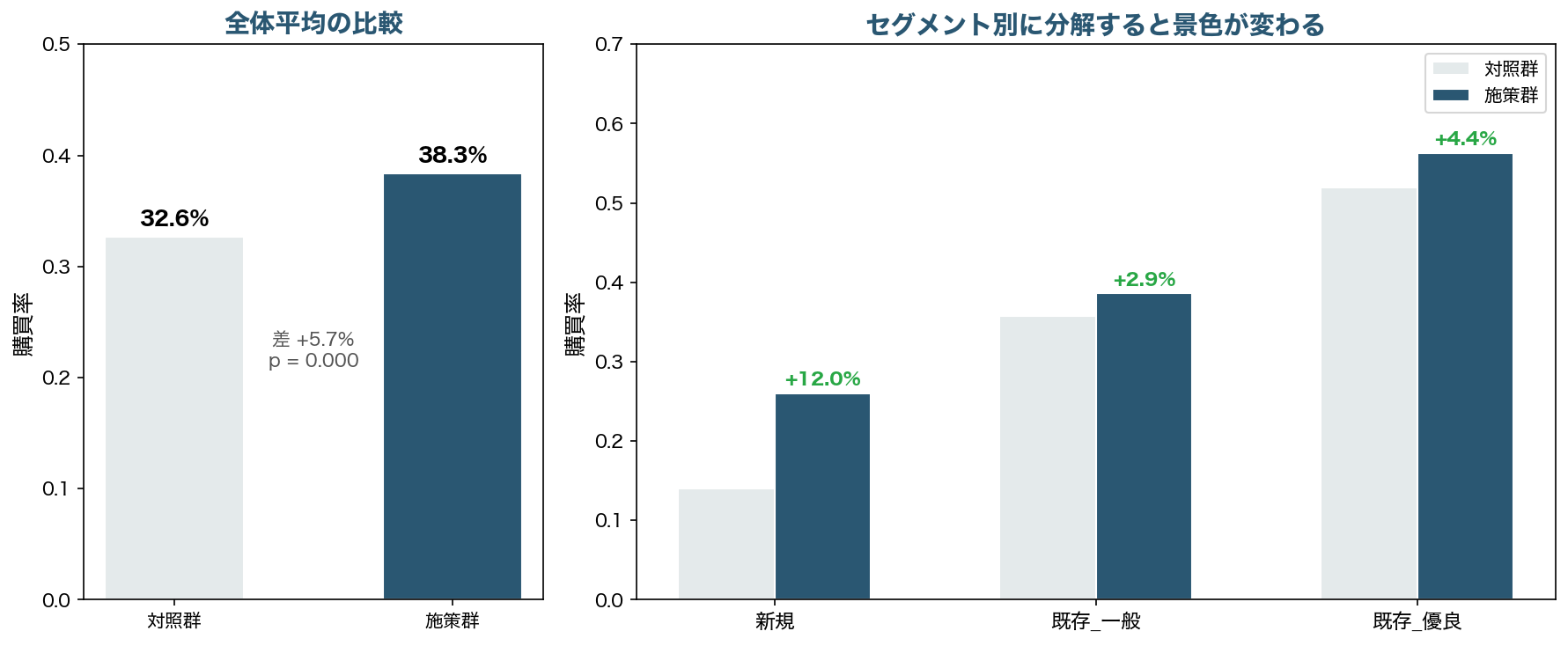
全体平均で見ると、購買率は32.6%から38.3%に上昇し、p値は0.001未満。BIダッシュボードに棒グラフを出せば「施策は成功」と見えるでしょう。
しかしセグメント別に分解すると景色が変わります。新規顧客では+12.0ポイントと大きな改善が見られますが、既存一般は+2.9ポイント、既存優良は+4.4ポイント。効き方がまったく異なります。
本当に知りたいのは、「全体で効いたか」だけではありません。どの顧客に、どの条件で効くのかです。この分解をしない限り、「全店展開すべきか、特定セグメントに絞るべきか」という実務的な判断ができません。
時系列のノイズが施策効果を隠す
小売データには、施策以外の変動要因が大量にあります。曜日、祝日、気温、降雨、競合販促、給料日。これらのノイズは施策効果よりも大きいことが珍しくありません。
今回のシミュレーションでは、施策群に全体で+2%程度の売上リフトを設定しました。この差が日次の生データでどう見えるかを確認します。
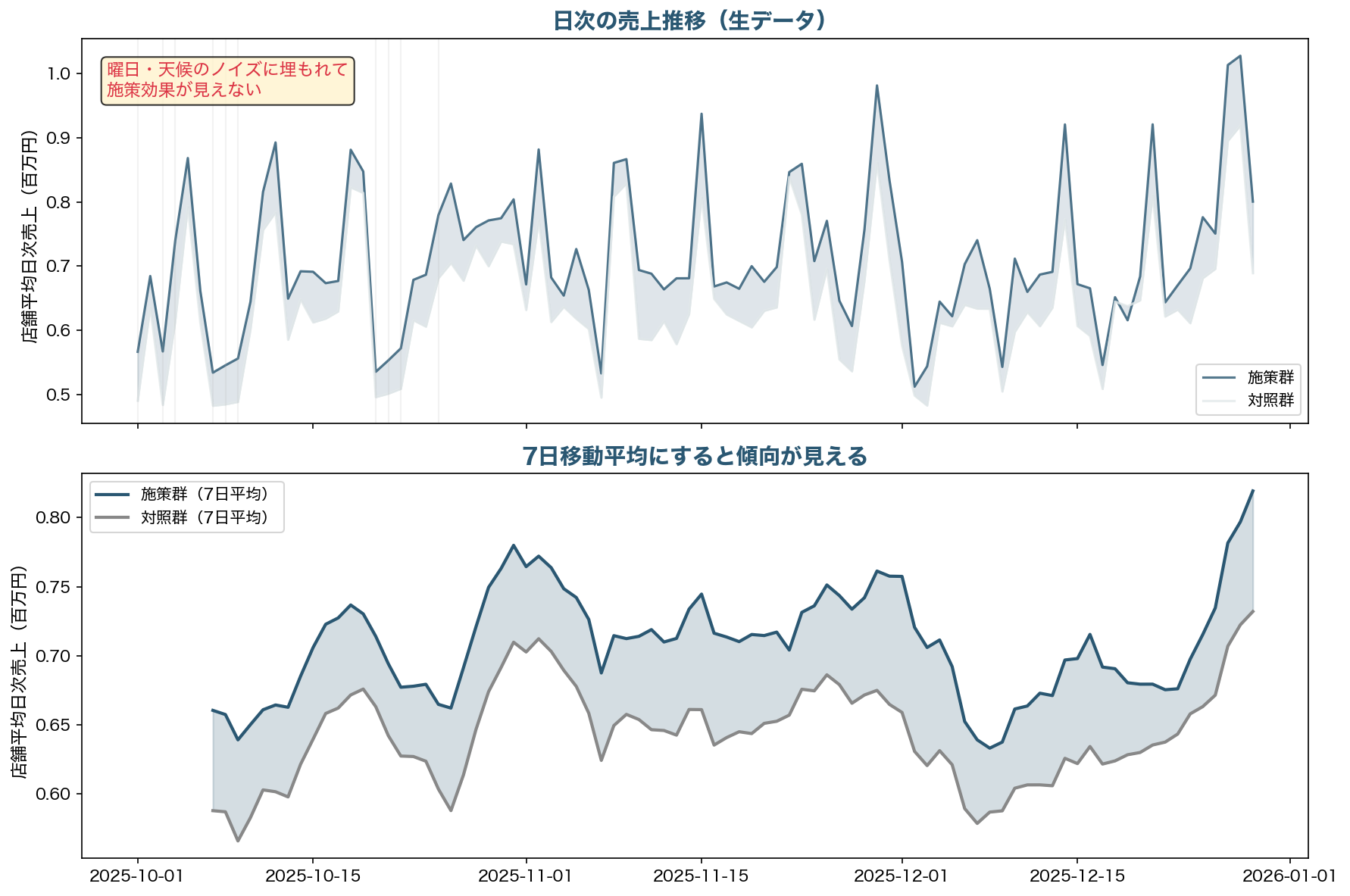
上段の生データを見てください。施策群(青)と対照群(灰)の日次売上は激しく上下しており、どちらが高いのかほとんど判別できません。週末のスパイクと平日の谷、雨の日の急落が支配的で、+2%の施策効果は完全に埋もれています。
7日移動平均にすると、ようやく施策群がわずかに上を推移している傾向が見えてきます。しかしこれでも、11月下旬のように差が縮まる期間もあり、単純に「施策群の方が高い日が多かった」では結論になりません。
A/Bテストでランダム化していれば理論上は平均化されるという考え方もありますが、実務では店舗単位の偏り、サンプルサイズ不足、運用上の割付の歪みが普通に起こります。時系列要因を十分に扱わないままの単純比較は、簡単に判断を誤ります。
BIダッシュボードの落とし穴
BIツールで「施策群 vs 対照群」の日次折れ線グラフを作ること自体は簡単です。しかし、目で見て「なんとなく施策群が高そう」という判断は、曜日や天候に引きずられた錯覚かもしれません。「差がある」と言い切るには、これらの外部要因を統計的に調整する手続きが必要です。
有意差が出ても、利益が出ているとは限らない
ここまで見てきた分析は、すべて「購買率」に注目していました。しかし小売の意思決定で最終的に重要なのは、売上ではなく利益です。
今回のクーポン施策は150円のクーポンを配布しています。購買率が上がっても、クーポン原資が粗利を食っていたら、施策としては失敗です。全セグメントで購買率が改善していたこの施策を、利益ベースで見直してみましょう。
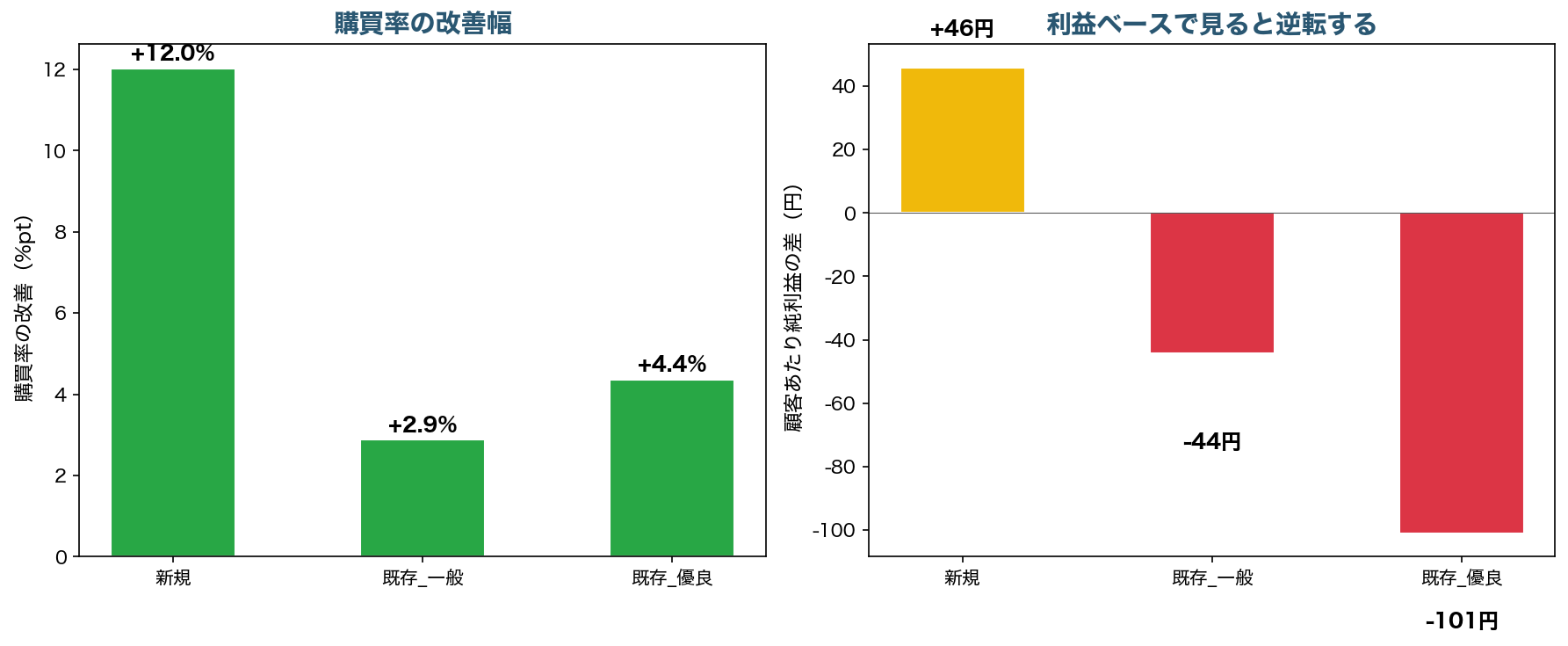
左のグラフを見てください。購買率は新規で+12.0ポイント、既存一般で+2.9ポイント、既存優良で+4.4ポイントと、すべてのセグメントで改善しています。
ところが右のグラフでは、景色が一変します。顧客あたりの純利益(粗利 − クーポン原資)で見ると、新規は+46円とプラスですが、既存一般は−44円、既存優良は−101円とマイナスです。購買率は全セグメントで改善しているのに、利益が出ているのは新規だけ。
特に既存優良はもともと購買率が高い層です。クーポンがなくても55%の確率で買う顧客に150円の割引を出しているため、利益毀損が最も大きくなっています。全体で見ると、新規のプラスを既存のマイナスが上回り、顧客あたり−31円の損失です。
この分析で浮かぶ問い
- 新規顧客だけに絞ってクーポンを配れば、利益はプラスに転じるのか
- クーポン額を100円に下げたら、購買率の改善幅はどこまで縮むのか
- 短期の利益はマイナスでも、新規のLTV(生涯価値)を考えるとプラスになるのか
これらの問いは、A/Bテストの「有意差あり/なし」からは一切出てきません。
ベイズ推定とは何か、なぜ施策検証に向いているのか
ここまでの分析で、「購買率は有意に上がったが、利益はマイナスだった」ということが分かりました。では、この施策にGoを出すべきかどうか。ここからはベイズ推定という考え方を使って、この問いに答えていきます。
ベイズ推定の基本的な考え方
一般的なA/Bテスト(頻度論的アプローチ)では、「施策群と対照群に差がない」という仮説を立て、それが棄却できるかどうかをp値で判定します。結果は「有意差あり(p < 0.05)」か「有意差なし」の二択です。
ベイズ推定は発想が違います。データを観測した後に、「施策効果はどのくらいの値を取りそうか」という確率分布を直接求めます。これを事後分布と呼びます。たとえば「購買率の改善幅は2%〜8%の間にありそうで、中央値は5%」というように、効果の大きさと不確実性の幅をセットで得られます。
なぜ施策の意思決定にベイズが向いているのか
小売の意思決定で本当に知りたいのは「p値が0.05未満か」ではなく、「この施策に投資して利益が出る確率はどのくらいか」です。ベイズ推定なら、この問いに直接答えられます。
| 知りたいこと | 従来のA/Bテスト(頻度論) | ベイズ推定 |
|---|---|---|
| 施策は効いたか | 「有意差あり」or「なし」の二択 | 「効果がプラスである確率は94%」のように確信度を数値化 |
| 効果はどのくらいか | 点推定+信頼区間(解釈が難しい) | 事後分布として確率的に表現 |
| 投資判断に使えるか | 「p < 0.05だからGoで良いか?」と悩む | 「利益がプラスになる確率6%」→ 明確にNG |
| テスト途中で判断したい | 途中で見るとp値が信頼できなくなる | データが増えるたびに分布を更新でき、いつでも判断可能 |
| データが少ない場合 | サンプルサイズ不足で判定不能 | 事前情報を活用し、少ないデータでも推定可能(不確実性は大きいまま残る) |
特に小売では「テスト結果を日々見ながら判断したい」「店舗数が少なくてデータが限られる」「経営層にp値を説明しても伝わらない」という場面が多くあります。ベイズ推定はこれらすべてに対して自然な解を提供します。
では、今回のクーポン施策のデータに実際にベイズ推定を適用してみましょう。
ベイズ推定で今回の施策を評価してみる
購買率の事後分布をセグメント別に見る
まず、各セグメントの購買率をベイズ推定(Beta-Binomial モデル)で求めてみます。「施策群の購買率はいくつか」という点推定ではなく、「どのあたりの値を取りそうか」という分布で捉えます。
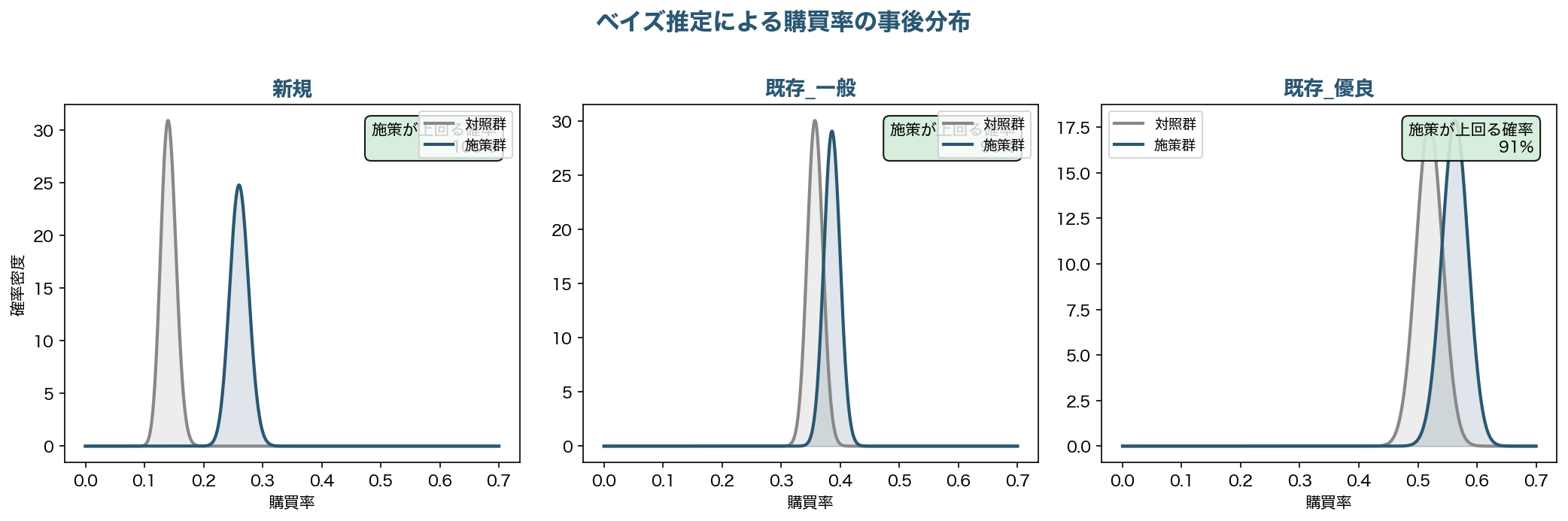
新規顧客では、対照群(灰)と施策群(青)の分布がほぼ完全に分離しています。施策が購買率を上回る確率はほぼ100%で、これは確信を持って言える結果です。
一方、既存優良では分布が大きく重なっています。施策が上回る確率は91%。高いように見えますが、「10回に1回は効いていない可能性がある」とも読めます。しかもこのセグメントは先ほど見たとおり、利益ベースでは最も損失が大きい層です。
「有意差あり/なし」の二択ではなく、「どのくらいの確信度で効いているか」を数値で出せることがベイズ推定の強みです。
「この施策に投資すべきか」を利益の確率分布で答える
最終的な意思決定は「購買率が上がったか」ではなく「利益が出るか」です。全顧客を対象にクーポンを配った場合の、顧客あたり純利益の改善額をベイズ的に推定してみます。
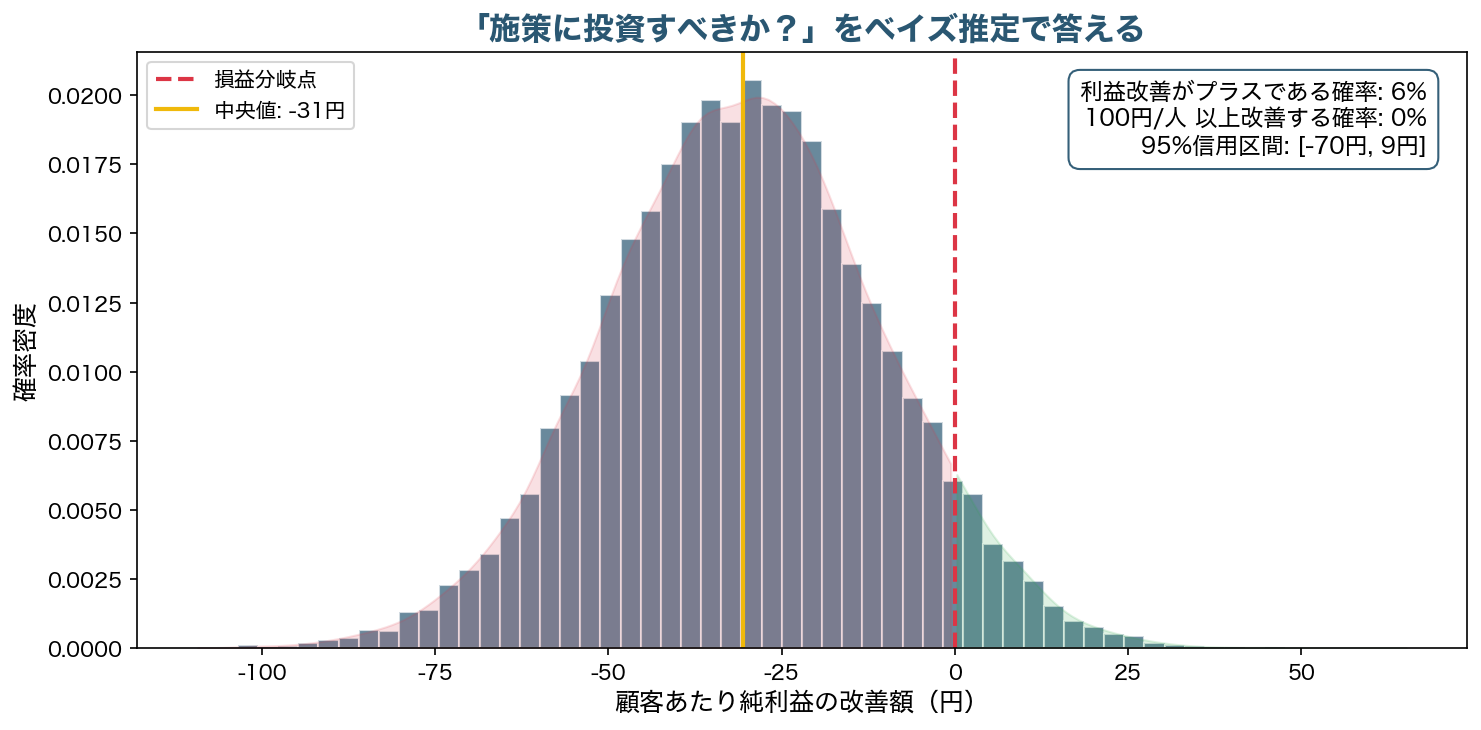
結果は明快です。純利益の改善額は中央値で−31円。95%信用区間は−70円〜+9円で、プラスになる確率は約6%。つまりこの施策を全顧客対象で実施する限り、利益が出る見込みはかなり低いということになります。ただし新規顧客だけに絞れば話は別です。このように「全体はNG、特定セグメントならGo」という判断ができるのが、セグメント分解とベイズ推定を組み合わせる強みです。
これが意思決定に使える情報です。p値が0.001未満だから成功、ではない。「利益がプラスになる確率は何%か」「投資回収できる確率はどのくらいか」。経営が本当に知りたいのは、こちらの答えです。
ベイズ推定が意思決定に適している理由
- 「有意差あり/なし」ではなく、「購買率が上回る確率は91%」のように確信度を数値で表現できる
- 「粗利改善が100円以上になる確率」のように、事業上の閾値に対する確率を直接計算できる
- データが少ない段階でも、全体情報を借りながら極端な推定を抑えることができる
- テスト途中でも結果を逐次更新できるため、「いつ止めるか」の判断にも使える
BIの集計やLLMの要約では、なぜ不十分なのか
ここまでの分析をBIダッシュボードやLLM(ChatGPT等)で代替できるかを考えてみます。
BIツールでできること・できないこと
BIツール(Tableau、Power BI、Looker Studioなど)は、集計と可視化が得意です。施策群/対照群の購買率の棒グラフ、セグメント別のクロス集計、日次の折れ線グラフ。ここまでは問題なく作れます。
しかし、BIツールの本質は「過去の事実を集計して見せること」です。以下のような問いには答えられません。
| 問い | BIツール | 統計モデル |
|---|---|---|
| 購買率の差は偶然ではないと言えるか | 判断できない | p値や事後確率で定量化 |
| 曜日・天候の影響を除いた施策効果は | フィルタはできるが調整はできない | 回帰モデルで外部要因を調整 |
| 利益がプラスになる確率は何%か | 計算できない | ベイズ事後分布から直接算出 |
| 新規だけに絞ったときのROI予測 | 過去実績のフィルタ表示のみ | 階層モデルでセグメント別推定 |
BIツールは「何が起きたか」を見るには最適ですが、「何をすべきか」を判断する道具ではありません。ダッシュボード上の数字を見て「施策群が高いからOK」と結論づけてしまうと、今回のケースのように利益がマイナスの施策にGoを出してしまう危険があります。
LLMに聞いて済むのか
最近はChatGPTやClaudeに「このA/Bテストの結果を分析して」と聞く場面も増えています。LLMはデータを要約し、もっともらしい解釈を返すことが得意です。
しかしLLMの弱点は、集計結果を「言葉で説明する」ことと「統計的に検証する」ことを混同しやすい点です。たとえば「施策群の購買率が38.3%で対照群が32.6%なので、施策は有効と考えられます」というLLMの回答は、今回のケースでは完全に間違った結論です。購買率は確かに上がっていますが、新規を除く既存セグメントでは利益がマイナスで、全体でも赤字だからです。
LLMは外部要因の調整、信用区間の計算、事後分布の推定といった統計的手続きは行いません。データを「読んで要約する」のと「モデルを立てて推定する」のは根本的に別の行為です。
意思決定の場面でLLMに頼りすぎるリスク
LLMは「施策群の方が数字が高い→施策は有効」という表層的なパターンで回答しがちです。利益構造や交絡要因まで踏み込んだ分析は、統計モデルを組んで初めて可能になります。LLMは仮説の整理や分析方針のディスカッションには有効ですが、最終的な施策判断を委ねるべきツールではありません。
では、何が必要なのか
重要なのは、A/Bテストをやめることではありません。A/Bテストを入口にしつつ、その結果を正しく読むための統計的な補強を行うことです。今回のシミュレーションから見えた、必要な分析の視点を整理します。
1. 効果の異質性を見る
誰に効いたかを見ます。平均差だけでなく、顧客属性、購買履歴、店舗特性ごとに効果が異なる前提で分析します。今回のケースでは、全体で+5.7ポイントの購買率改善でしたが、新規に+12.0、既存優良に+4.4と、効き方がまったく異なっていました。施策の対象を新規に絞るか全顧客に展開するかで、利益構造が根本的に変わります。
2. 時系列や外部要因を調整する
曜日、季節性、天候、競合キャンペーンなどを考慮します。日次データで見たとおり、±12%のノイズの中に+2%の施策効果が埋もれていました。単純な前後比較や二群比較で済ませず、外部要因を統計的にコントロールすることが必要です。
3. 利益ベースで評価する
売上ではなく、粗利、割引原資、再来店への影響まで含めて見ます。「売れた」ではなく「儲かったか」で判断します。今回のケースでは、購買率が全セグメントで改善していたにもかかわらず、新規顧客だけは+46円のプラスでしたが、既存顧客では大きくマイナスとなり、全体では赤字でした。この逆転は購買率だけを見ていたら絶対に気づけません。
4. 不確実性を意思決定に使える形で表現する
単に「有意差あり/なし」ではなく、「効果がプラスである確率」「粗利改善が一定以上である確率」のように、経営判断に近い形で結果を表現します。今回の事後分布は「利益改善がプラスになる確率は約6%」と示しました。この表現であれば、統計の専門知識がなくても意思決定ができます。
5. 長期効果を視野に入れる
短期の購買率upliftだけでなく、反動減や値引き依存、LTVへの影響を見る必要があります。強い値引き施策は一時的に売上を押し上げますが、顧客が「割引時しか買わない」状態に慣れると、将来の定価購買を削るかもしれません。
| 分析の視点 | 「ただのA/Bテスト」 | 統計モデルによる補強 |
|---|---|---|
| 効果の見方 | 全体平均の差 | セグメント別・店舗別の効果分解 |
| 外部要因 | ランダム化に頼る | 回帰・差分の差分法で調整 |
| 評価指標 | 購買率・売上 | 純利益・ROI・LTV |
| 判断基準 | p < 0.05 で有意差あり | 利益改善がプラスの確率 X% |
| 時間軸 | テスト期間のみ | 短期 + 長期(LTV・反動減) |
まとめ
今回のシミュレーションでは、「A/Bテストで有意差あり(p < 0.001)、購買率+5.7ポイント改善」という結果が、利益ベースで見ると顧客あたり−31円の損失だったことを示しました。新規顧客だけは+46円のプラスでしたが、既存顧客ではマイナスが上回りました。
BIダッシュボードで棒グラフを並べれば「施策は成功」に見えます。LLMに聞けば「購買率が有意に向上しており、施策は有効と考えられます」と返ってくるでしょう。しかし実態は、全顧客対象では利益がマイナスの施策でした。一方で、新規に絞れば利益が出る可能性がある。この判断は、セグメント分解と利益ベース評価をしなければ到達できません。
小売マーケティングで本当に重要なのは、単に「施策が効いたか」ではありません。
- 誰に効いたのか
- どの店舗で再現するのか
- 売上ではなく利益で見てどうか
- 短期だけでなく長期でどうか
- どのくらいの確からしさでそう言えるのか
ここまで見て初めて、施策の評価が意思決定につながります。
A/Bテストは出発点として有効です。ただし、それだけで十分だと思った瞬間に危うくなる。これからの施策検証では、「A/Bテストをするかどうか」ではなく、「A/Bテストの先まで見られているかどうか」が問われるのだと考えています。