前回の基礎編では、「広告を見た人ほど買っている」は広告が効いた証拠とは限らないこと、そして本当の効果は「もし広告を打たなかったら」との差で考えることをお話ししました。今回はその実践編です。架空の食品スーパーチェーンが一部の店舗で折込チラシと店舗近隣の地域広告を打った、という設定のダミーデータ(教材用に作った架空データ)を用意し、同じデータを3つの方法で分析します。単純な比較がどれほど効果を水増しするか、因果推論の手法がどこまで真実に近づくかを、グラフで見比べましょう。
この記事の数値は、解説のために架空の設定で生成したダミーデータを分析した結果です。実在する企業や店舗のデータではありません。データは「真の広告効果は売上+9%」とわかった状態で作っているため、各手法がこの正解にどれだけ近づけるかを答え合わせできます。
舞台設定——どんなデータを用意したか
全40店舗を持つ食品スーパーチェーンを想定します。2025年10月、本部はこのうち一部の店舗エリアで折込チラシと地域広告のキャンペーンを実施しました。2025年4月から12月までの週ごとの売上を、全店について記録してあります。ここで現実によく起きる“偏り”をわざと仕込んでいます。キャンペーンの対象に選ばれたのは、売場面積が大きく都心に近い大型店に偏っている、という点です。販促は目立つ大型店から始めたくなるものですが、これがセレクションバイアス(比較する2グループが最初から別物になる歪み)の正体になります。
| 項目 | 内容 |
|---|---|
| 店舗数 | 全40店舗(広告あり20店 / 広告なし20店) |
| 期間 | 2025年4月〜12月の週次売上(施策開始は10月) |
| 店舗の属性 | 売場面積・立地(都心/郊外/住宅街)・駅からの距離・会員数 |
| 仕込んだ偏り | 大型・都心の店ほど広告対象に選ばれやすい(セレクションバイアス) |
| 仕込んだ季節要因 | 年末需要で全店共通に売上が伸びる |
| 真の広告効果 | 広告対象店の売上を+9%押し上げる(これが正解) |
方法1 単純比較——いちばんやりがちで、いちばん危ない
こうした偏りは、わざとらしい仮定ではなく、現実のキャンペーンでよく起きることです。販促予算には限りがあるため、まずは集客力のある旗艦店から試したくなりますし、効果が出やすそうな店を優先するのは自然な判断です。問題は、その自然な判断が、後から効果を測るときに比較をゆがめてしまう点にあります。広告を当てた店と当てなかった店が最初から別物であれば、両者の売上の差には広告以外の理由がたっぷり含まれてしまいます。では、その状態でよくある測り方をすると、どれほど結論がずれるのかを見ていきます。
まず、現場で最もよく使われる2つの単純比較を試します。1つ目は「広告を出した店」と「出さなかった店」の、キャンペーン期間中の平均売上をそのまま比べる方法です。広告ありの店は週あたり平均5,901千円、広告なしの店は4,183千円でした。差は約41%。これだけ見れば「広告で売上が4割増えた」と言いたくなります。しかしこの差の大半は、広告対象がもともと売上の大きい大型店に偏っていたことの反映です。広告の力ではなく、店の大きさの差を見ているにすぎません。
2つ目は「広告を出した店の、キャンペーン前と後」を比べる方法です。広告対象店は施策前の4,670千円から施策後の5,901千円へ、約26%伸びました。一見すると効果は明らかに見えます。ところが同じ期間、広告を出していない店も年末需要で+15%伸びています。つまり26%のうち大部分は、広告がなくても起きていた季節の伸びです。前後比較は、この季節要因をまるごと広告の手柄に数えてしまいます。
店舗どうしの単純比較は+41%、施策前後の単純比較は+26%。どちらも真の効果+9%を大きく超えています。単純比較は、店の規模差や季節要因といった「広告以外の理由」を効果に混ぜ込んでしまうため、効果を過大評価するのです。
方法2 差分の差分法(DiD)——季節と店舗差を同時に消す
ここで登場するのが差分の差分法(DiD=処置群と対照群それぞれの「前後の変化」をとり、その差を効果とみなす手法)です。考え方はシンプルです。広告を出さなかった店の「前後の変化」は、広告がなかった世界で広告対象店にも起きていたはずの変化、つまり反実仮想の代役になります。広告対象店の変化から、この対照群の変化を差し引けば、季節などの共通要因が相殺され、広告だけの効果が残ります。
DiDが成り立つ鍵は平行トレンド仮定(へいこうトレンドかてい=広告がなければ、両グループの売上は同じように動いていたはず、という前提)です。これは施策前のデータで目で確かめられます。次のグラフを見てください。キャンペーン開始(縦の点線)より前は、広告ありの店と広告なしの店が、水準こそ違えど同じリズムでほぼ平行に動いています。そして施策開始後、広告ありの店だけが対照群を上回って跳ね上がっています。この“上振れ”の幅こそが、季節要因を除いた広告の純粋な効果です。
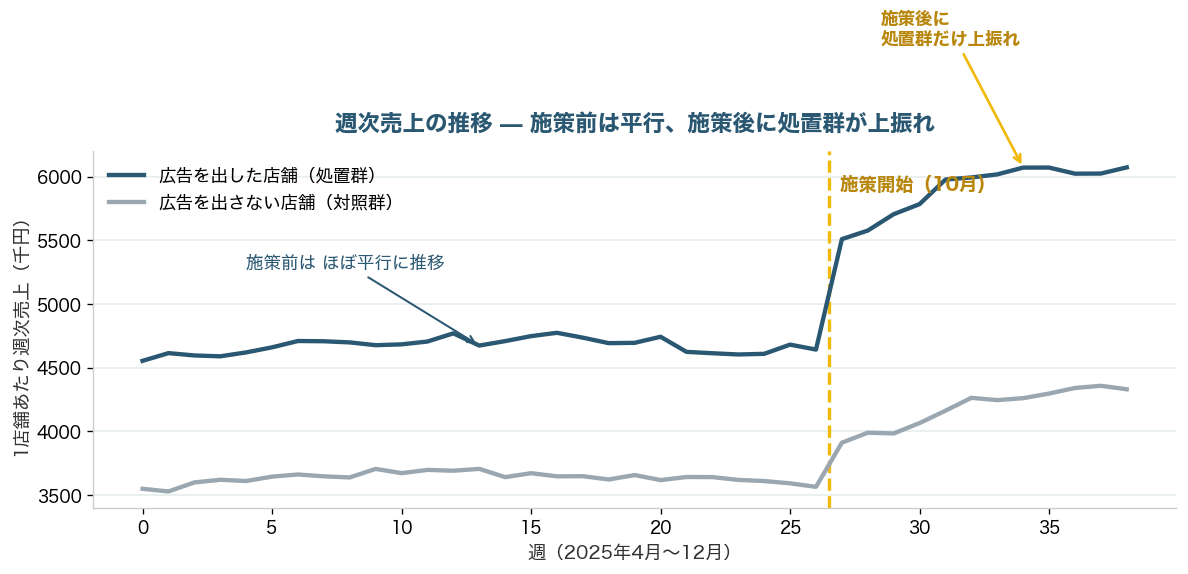
数字で整理すると次の表のようになります。対照群(広告なし)は季節要因で+15.1%伸び、処置群(広告あり)は+26.4%伸びました。その差し引きが、季節を除いた広告の効果です。
| 施策前→施策後の伸び | |
|---|---|
| 広告を出した店(処置群) | +26.4% |
| 広告を出さない店(対照群) | +15.1%(季節要因) |
| 差し引き(広告の効果) | 処置群の伸びから季節分を引いた残り |
店舗ごとの規模の違いと、週ごとの季節パターンをていねいに取り除く標準的なDiD分析を行うと、広告の効果は+9.7%(95%信頼区間で8.8〜10.6%)と推定されました。仕込んでおいた真の効果+9%に、見事にほぼ一致します。単純比較が4割・3割と水増ししていたのに対し、DiDは正解を当てたわけです。
方法3 傾向スコアマッチング——似た者どうしの店をペアにする
もう1つの代表的な手法が傾向スコアマッチング(けいこうスコアマッチング=広告が当たりやすさの似た者どうしをペアにして比べる方法)です。DiDが「前後の変化」で勝負するのに対し、こちらは「広告対象になりそうな度合い」を店ごとに計算し、その度合いが近い広告なしの店を、各広告対象店の“双子”として選び出します。売場面積も立地も会員数も似た店どうしを比べれば、店の規模差という偏りを取り除けるという発想です。
マッチングがうまくいったかは、ペアにする前と後で、両グループの属性がどれだけそろったかで確かめます。次のグラフは、店舗属性の差の大きさをマッチング前後で比べたものです。マッチング前は売場面積や施策前売上に大きな差がありましたが、マッチング後はその差がぐっと縮まり、似た店どうしを比べられる状態になっています。
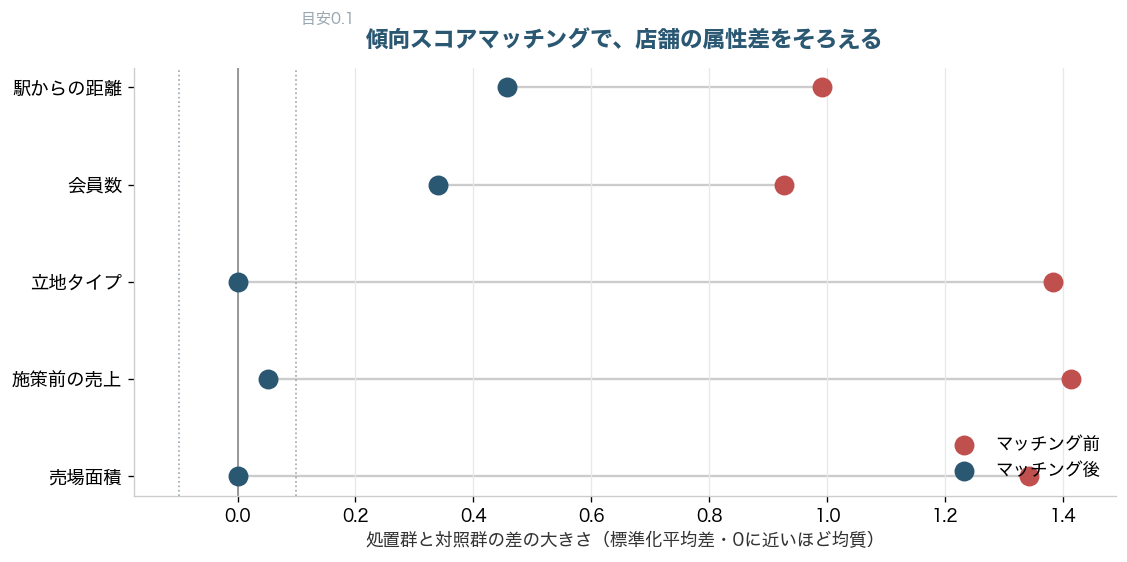
この方法で推定した広告効果は+12.2%でした。単純比較の41%・26%に比べれば、真の+9%にぐっと近づいています。ただしDiDの+9.7%ほどはぴたりと当たりませんでした。理由はグラフにも表れています。駅からの距離や会員数の差は、マッチング後も完全には消えていません。傾向スコアマッチングは「測れている属性」しかそろえられないため、測り損ねた要因が残ると、その分だけ推定がずれます。これは手法の弱点であると同時に、後で触れる重要な教訓につながります。
3つの方法を並べてみる
ここまでの結果を1枚にまとめます。同じデータを使っているのに、方法によって結論がこれほど変わります。
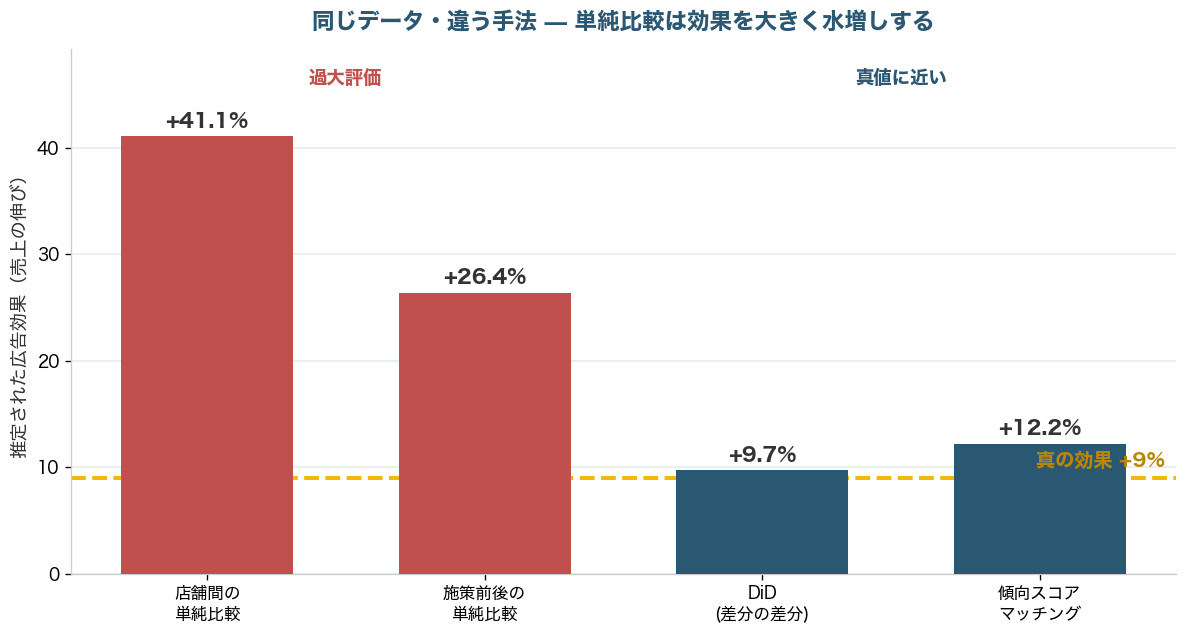
| 手法 | 推定した広告効果 | 真値+9%との関係 |
|---|---|---|
| 店舗間の単純比較 | +41.1% | 4倍以上に水増し |
| 施策前後の単純比較 | +26.4% | 約3倍に水増し |
| 差分の差分法(DiD) | +9.7% | ほぼ一致 |
| 傾向スコアマッチング | +12.2% | 近いが少し過大 |
もしこの会社が店舗間の単純比較を信じて「広告は売上を4割上げる」と判断していたら、本来の4倍以上の効果を見込んで広告予算を増やし続けたでしょう。実際の上乗せは+9%。投じた費用に見合っていたかどうかは、正しく測って初めてわかります。広告の良し悪しを語る前に、まず効果を正しく測れているかを疑うことが、無駄な投資を止める第一歩です。社内に散らばる売上データをどう集約して分析につなげるかは、Snowflakeで売上ダッシュボードを作る記事も参考になります。
それでもDiDは万能ではない
今回はDiDが真の効果をきれいに当てましたが、いつでもそうなるわけではありません。DiDの土台は平行トレンド仮定、つまり「広告がなければ両グループは同じように動いていたはず」という前提でした。もしこの前提が崩れていたら、DiDも誤った答えを出します。
たとえば、広告対象に選んだ大型店が、キャンペーン前からすでに対照群より速いペースで成長していたとします。その場合、施策後に処置群が伸びても、それが広告のおかげなのか、もとからの成長の勢いなのかを区別できません。グラフで施策前のトレンドが平行でなく開きつつあったら、DiDの結論は疑うべきです。だからこそ、効果を測る前に施策前のデータで平行トレンドを目で確認する作業が欠かせません。手法を回せば数字は出ますが、その数字が信じられるかどうかは前提しだいなのです。
数字は出た。でも、最後に効くのは人間の判断
ここまで読むと「では分析ツールやAIに任せれば自動で正しい数字が出るのでは」と思うかもしれません。しかし、今回の手順を振り返ると、最も重要な判断はすべて人間がしていることに気づきます。どの店舗を対照群に選ぶか。平行トレンドが現実的に成り立っていそうか。どんな属性を“そろえるべき要因”として持ち込むか。傾向スコアマッチングが少しずれたのも、駅距離や会員数という測りきれない要因が残ったからでした。何を測り、何を疑うべきかは、その事業と現場を知る人の仮説に依存します。
AIは、与えられたデータと前提のもとで計算を高速にこなし、分析を大きく加速してくれます。けれども「この比較は妥当か」「隠れた要因は何か」という問いの設計と、出た数字をビジネスの文脈で解釈する仕事は、人間が引き受けるしかありません。専門領域の知識や現場の仮説は、そのすべてをAIにコンテキストとして渡しきれないからです。効果検証は、AIに丸投げできない領域の代表例です。だからこそ、AIに分析を任せる時代ほど、因果の考え方を理解した人間の価値が上がります。AIをどう業務に組み込むかの考え方は「AIを入れる」から「安全に回す」へでも整理しています。
まとめ
同じデータでも、測り方しだいで広告効果は+9%にも+41%にも見えます。店舗どうしの単純比較は店の規模差を、施策前後の単純比較は季節要因を、効果に混ぜ込んで水増しします。差分の差分法は対照群を反実仮想の代役に使って季節と店舗差を同時に消し、真の効果を言い当てました。傾向スコアマッチングも似た店どうしを比べて真値に近づきましたが、測りきれない要因が残ると少しずれます。そして、どの手法を選び、前提が妥当かを判断し、数字を解釈するのは人間の仕事です。広告効果の検証は、正しく測ることと、正しく問いを立てることの両輪で初めて意味を持ちます。基礎編とあわせて、自社の効果測定を見直すきっかけになれば幸いです。続く発展編(合成コントロール法)では、対照地域が見つからないときの測り方も紹介しています。
広告効果検証 適用判断チェック
- 問1
あなたが食品スーパーチェーンのマーケ責任者で、地域広告キャンペーン後に「広告を出した店と出さなかった店」の平均売上を比べたら、広告ありが約4割高い結果になりました。本記事の主張に従うと、この差をどう解釈すべきか?
解説本記事のダミーデータでは、店舗どうしの単純比較は+41.1%、真の広告効果は+9%でした。「広告対象がもともと売上の大きい大型店に偏っていたことの反映」「広告の力ではなく、店の大きさの差を見ているにすぎません」と明示されています。誤答 (1) は本記事が4倍以上の水増しと警告する判断、(3) は有意性を測ってもバイアスは消えず、(4) は前後比較も季節要因をまるごと広告の手柄にしてしまうと本記事が指摘しています。 - 問2
あなたが広告対象店舗で差分の差分法 (DiD) を回す前に、施策前のデータで処置群と対照群の売上推移をグラフ化してみたところ、施策前から処置群の伸びの方が明らかに早く、両群の差が広がりつつありました。本記事の主張に従うと、どう判断すべきか?
解説本記事は「DiDの土台は平行トレンド仮定」「もしこの前提が崩れていたら、DiDも誤った答えを出します」「グラフで施策前のトレンドが平行でなく開きつつあったら、DiDの結論は疑うべきです」と明示しています。誤答 (1) は前提が崩れた分析をそのまま採用する判断、(3) は都合の良い期間だけ切り出す行為で結果が恣意的になり、(4) は対照群の質を下げて反実仮想の代役にならなくしてしまいます。 - 問3
あなたが分析チームで傾向スコアマッチングを試したところ、マッチング後も「駅からの距離」と「会員数」の差が完全には消えていないことに気づきました。本記事の主張に従うと、どう向き合うべきか?
解説本記事は傾向スコアマッチングが+12.2%と真値+9%より少し過大に出た理由を「駅からの距離や会員数の差は、マッチング後も完全には消えていません」「傾向スコアマッチングは『測れている属性』しかそろえられないため、測り損ねた要因が残ると、その分だけ推定がずれます」と説明しています。誤答 (1)(3) は弱点を無視する判断、(4) は重要属性を切り捨てて分析の妥当性をさらに損ねます。 - 問4
あなたが社内で「効果検証を AI に丸投げできないか」という声を受けています。本記事の主張に従って答えるなら、どれが最も適切か?
解説本記事は「効果検証は、AIに丸投げできない領域の代表例」「『この比較は妥当か』『隠れた要因は何か』という問いの設計と、出た数字をビジネスの文脈で解釈する仕事は、人間が引き受けるしかありません」と明示しています。誤答 (1) は本記事が真っ向から否定する主張、(3) は AI の計算高速化メリットを捨てるオーバーリアクション、(4) は人を増やせば解決すると誤解しており、本質は「問いの設計」が人間に残るという点です。
データに基づく意思決定を、はてなベースが伴走します
効果検証は「分析の前」が9割です。どのデータを揃え、どんな仮説を立て、何と何を比べるか。ここが整っていないと、どんな高度な手法も誤った結論を出します。はてなベースでは、データに基づく意思決定の土台づくりを支援しています。たとえばこんなケースでお役に立てます。
その広告効果、正しく測れていますか
散在するデータを集約して分析の土台をつくるデータ基盤の整備、効果検証や仮説設計に伴走する分析・AI活用の支援、そして「全社で安全にAIを使いたい」という方へのオンプレミスAI導入支援まで、貴社の状況に合わせて伴走します。まずは無料相談でお気軽にご相談ください。