ECサイトで新しいボタンや「あと◯円で送料無料」バーを試す。3日ほど様子を見て、数字が良さそうだから本実装する。よくある進め方です。そして、その判断の多くは、思っているより根拠が薄いものです。A/Bテストは、対象をランダムに2つに分けて比べる、効果検証のなかで最も信頼できる方法です。にもかかわらず、止め方ひとつで、ただの偶然を「効果あり」と勘違いしてしまう。この記事では、ECのA/Bテストでやりがちな3つの早とちりを、ダミーデータのシミュレーションで目に見える形にし、正しい回し方まで解説します。前回までの広告効果検証シリーズと同じく、数式やコードは使いません。
この記事のシミュレーション結果は、解説のために架空の設定で生成したダミーデータによるものです。実在するサイトのデータではありません。あえて「本当は効果がゼロ」とわかっている状況を作り、それでも誤判定が起きる様子を再現しています。
「いちばん確実」なはずのA/Bテストで、なぜ間違えるのか
A/Bテストの強みは、訪問者をくじ引きのようにランダムへ2グループに分ける点にあります。ランダムに分ければ、年齢も買う気もばらつきも平均的にそろい、残る違いは「新しい施策を見たかどうか」だけ。だから結果の差を、まるごと施策の効果と言い切れます。前回までの記事で見た差分の差分法や合成コントロール法が「広告なしの世界」を別の店舗や地域で代用していたのに対し、A/Bテストは同じ条件の集団を最初から2つに割って用意できる。理屈のうえでは、これ以上ない方法です。
用語メモ|A/Bテスト — 訪問者をランダムに2グループに分け、片方に元のページ(A)、もう片方に変更後のページ(B)を見せて、購入率などを比べる方法のこと。ランダムに分けることで条件がそろい、純粋に変更の効果を測れます。
ところが現場では、この強みが活かしきれずに判断を誤ります。やっかいなのは、間違いの原因が分析の手法そのものではなく、テストの「進め方」にある点です。手法は正しいのに、運用でつまずく。だから、統計に詳しい人でも、進め方のルールを決めていないと足をすくわれます。逆に言えば、ルールさえ押さえれば、専門知識がなくても大きな失敗は避けられます。とくにやりがちなのが、次の3つです。
落とし穴1 「のぞき見」——途中で止めると、偶然を効果と勘違いする
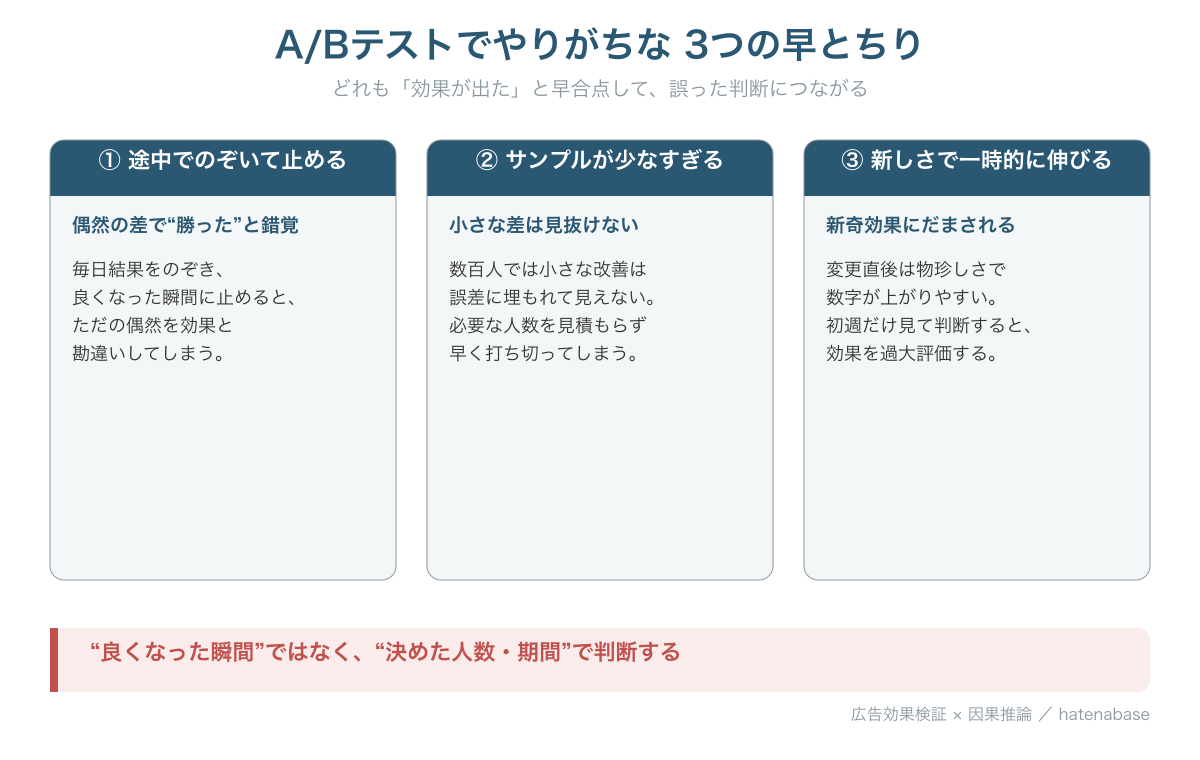
いちばん怖いのが、毎日結果をのぞいて、良くなった瞬間に止めてしまう進め方です。これを「のぞき見問題」と呼びます。問題を実感してもらうために、極端な設定で試します。AとBの中身をまったく同じにした、つまり本当は差がゼロのテストを、繰り返しシミュレーションしてみました。
用語メモ|有意差(統計的に有意) — 観測された差が「ただの偶然では説明しにくい」と言える状態のこと。よく使われる目安が「p値0.05」で、ざっくり言うと『本当は差がないのに、これだけの差が偶然出る確率が5%未満』を意味します。この基準は、正しく使えば誤判定を5%に抑える約束ごとです。
次のグラフは、その「差がゼロのテスト」を1本取り出したものです。日がたつにつれ、偶然のゆらぎで「差がありそう」に見える瞬間が訪れ、判定ラインを割り込みます。ここで止めれば「効果あり」と早とちりするでしょう。でも、最後まで回すと、差はちゃんと「なし」に戻っています。のぞき見は、この一瞬の偶然をすくい上げてしまうのです。
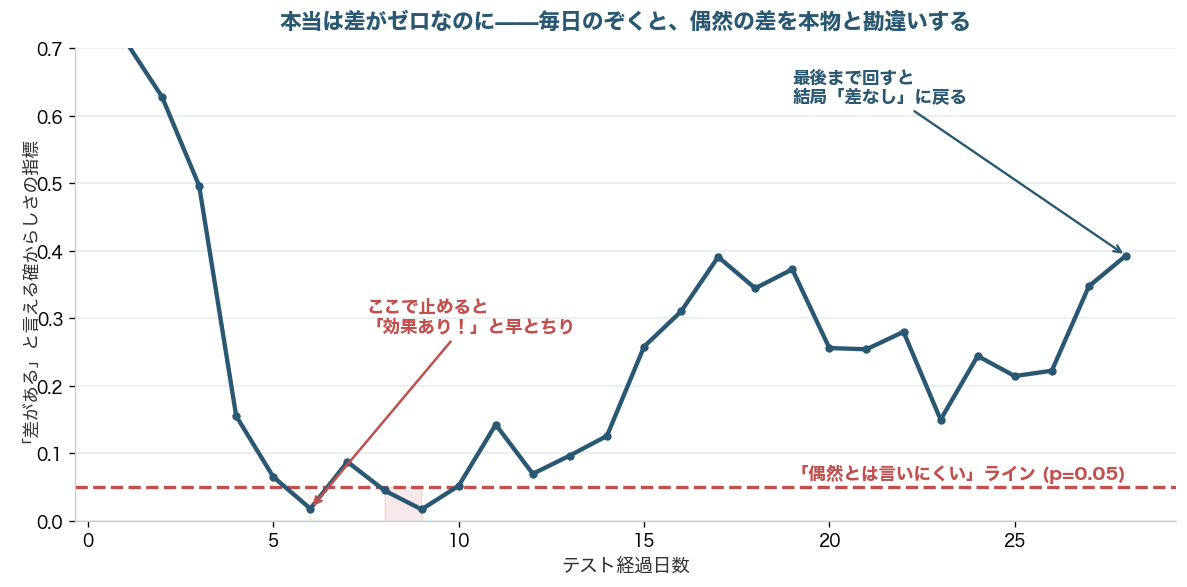
では、のぞき見はどれくらい危ないのか。同じ「差がゼロのテスト」を何千回もシミュレーションして、誤って「効果あり」と判定してしまう割合を測りました。テスト終了時に1回だけ判定する正しい運用なら、誤判定は4.9%。本来の約束どおり、ほぼ5%に収まります。ところが毎日のぞいて、良くなった瞬間に止める運用にすると、誤判定は23.4%まで跳ね上がりました。約5倍です。本当は何の効果もないのに、4回に1回は「勝った」と勘違いしてしまう計算になります。
なぜ、のぞくだけで誤判定が増えるのか。直感的にはこう考えてください。サイコロを1回振って6が出る確率は低いですが、何度も振り続ければ、いつかは6が出ます。のぞき見も同じで、毎日「差があるか」を確認するたびに小さなくじを引いているようなものです。引く回数が増えるほど、本当は差がないのに「たまたま大きな差」が出てしまう日に当たる確率は積み上がっていきます。1回しか引かなければ当たり(誤判定)は5%で済むのに、毎日引いて当たった瞬間に飛びつくと、確率はどんどん膨らむわけです。
用語メモ|のぞき見問題 — A/Bテストの途中で何度も結果を確認し、都合のよくなった時点で止めてしまうことで、偶然の差を本物と誤判定しやすくなる現象のこと。判定の回数を増やすほど、どこかで偶然が基準を超える確率が積み上がってしまうのが原因です。
落とし穴2 サンプルが少なすぎる——小さな改善は見抜けない
もうひとつの典型が、人数が足りないまま結論を出すことです。小さな改善ほど、必要な人数は跳ね上がります。次のグラフは、いまの購入率を3%として、どれだけの改善を見抜きたいかと、そのために1グループあたり何人必要かを示したものです。
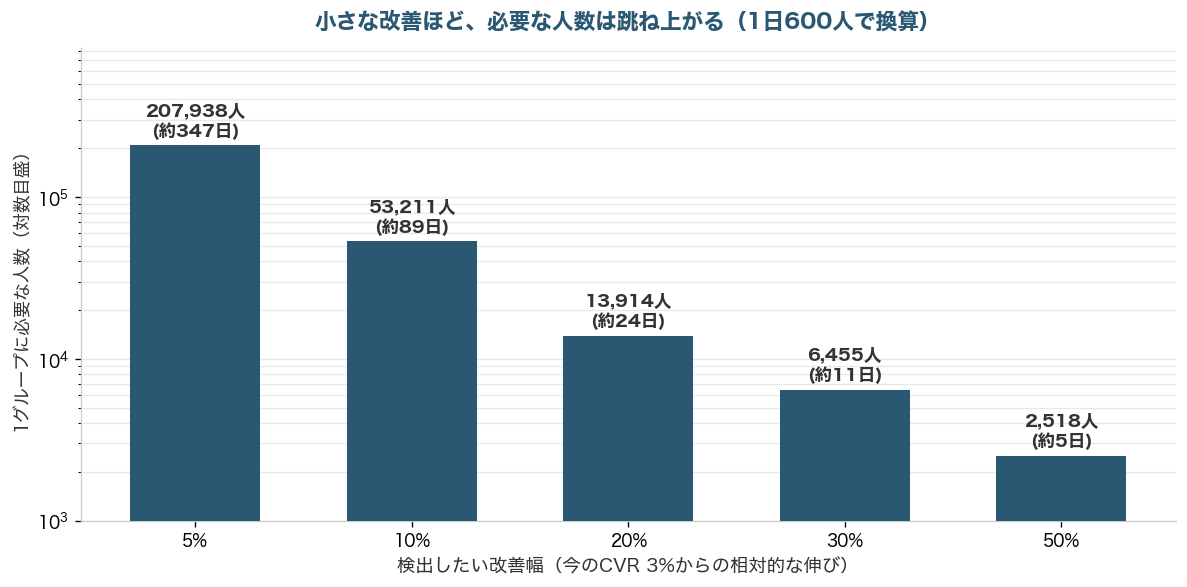
購入率を3%から3.15%へ、つまり+5%だけ改善したかを見抜くには、1グループあたり約21万人が必要です。1日600人ずつ集まるサイトなら、なんと347日かかる計算になります。+10%でも約5万3千人、89日。逆に+30%の大きな改善なら6千人ほどで足ります。ここでの教訓は、テストを始める前に「どれくらいの改善を、何人で見抜くか」を決めておくこと。それをせずに数百人で打ち切ると、本当はあった小さな改善を見逃したり、逆に偶然の差を拾ったりします。
この表は、中小規模のECにとってなかなか厳しい現実も突きつけます。アクセスが限られるサイトでは、ボタンの色のような小さな変更の効果を、現実的な期間で測りきるのは難しいのです。だとすれば、限られたテスト回数は、効果が大きく出そうな「打ち手の幅が大きい変更」に絞るのが賢明です。たとえば送料無料ラインの設定や、商品ページの構成そのものを変えるなど、+30%規模の差が見込める施策から優先する。小さなUIの微調整を延々とA/Bテストするより、よほど学びが早く積み上がります。
用語メモ|サンプルサイズ設計 — テストを始める前に、「どれくらいの改善を見抜きたいか」から逆算して、必要な人数と期間をあらかじめ決めておくこと。これを決めずに走り出すと、いつ止めればよいか分からず、のぞき見や早期終了の温床になります。
落とし穴3 新しさで一時的に伸びる——新奇効果
3つ目は、変更直後だけ数字が上がる現象です。新しいデザインやボタンは、見慣れない物珍しさから、最初の数日だけクリックや購入が伸びることがあります。これを新奇効果と呼びます。初週の好調だけを見て「効果あり」と判断すると、しばらくして数字が元に戻り、はしごを外されます。
とくにリピーターの多いECでは、これが起きやすくなります。たとえば、いつも使っている常連が、トップページの新しいバナーに気づいて思わずクリックする。最初の数日はクリック率がぐっと上がりますが、それは「効果」ではなく「目新しさへの一時的な反応」にすぎません。一巡して見慣れてしまえば、反応はもとの水準に戻ります。逆に、操作に慣れた常連が変更で一瞬とまどい、最初だけ数字が落ちることもあります。いずれにせよ、変更直後の数日は揺れやすい期間です。曜日による客層のばらつきと、この物珍しさが落ち着くまで、最低でも1〜2週間は回しきってから判断するのが安全です。
用語メモ|新奇効果(しんきこうか) — 変更したばかりのものが、新しさや物珍しさだけで一時的に良い反応を得る現象のこと。時間がたつと反応は落ち着くため、短期間だけ見て判断すると効果を過大評価してしまいます。
では、どう回せばいいのか
ここまで読むと気が重くなるかもしれませんが、難しい統計の知識がなくても、進め方のルールを決めておくだけで、3つの早とちりはほぼ防げます。共通する原則はただ一つ、「良くなった瞬間」ではなく「あらかじめ決めた人数・期間」で判断することです。テストを始める前に終わり方を決めておく、と言い換えてもいいでしょう。
- 始める前に人数と期間を決める — 見抜きたい改善幅から、必要なサンプル数とテスト期間を先に見積もる。
- 期間中はのぞいて止めない — 途中経過が良くても悪くても、決めた期間までは走りきる。
- 最低でも1〜2週間は回す — 曜日のばらつきと新奇効果が落ち着くまで待つ。
- 判定は最後に1回だけ — 終了時点の結果だけで、効果ありかどうかを決める。
この4つは地味に見えますが、効果は大きいものです。誤って「効果あり」と判断した変更を本実装すると、実際には売上が伸びないどころか、その施策を前提に次の改善を積み上げてしまい、土台ごと崩れます。早とちりのコストは、その場の判断ミスだけでなく、その後の意思決定にまで尾を引きます。だからこそ、テスト1本にかける時間を惜しまず、決めた人数と期間をやりきることが、結局はいちばんの近道になります。
それでも、何をテストするかは人間が決める
サンプルサイズの計算も、有意かどうかの判定も、いまはツールやAIが一瞬でやってくれます。けれど、そもそも何を仮説として立て、何をテストするか。出た結果を自社の文脈でどう読み解き、次の一手にどうつなげるか。ここは人間の仕事として残ります。「初週だけ伸びたのは新奇効果では」と疑えるのも、現場と商品を知っているからです。AIは計算を肩代わりしてくれますが、問いを立てる役割は引き受けてくれません。効果検証は、正しく測ることと、正しく問うことの両輪で初めて意味を持ちます。AIをどう業務に組み込むかは「AIを入れる」から「安全に回す」へでも整理しています。
まとめ
A/Bテストは効果検証の王道ですが、止め方を誤ると偶然を効果と勘違いします。毎日のぞいて良くなった瞬間に止めれば、本当は差がなくても4回に1回は「勝った」と早とちりする。小さな改善ほど必要な人数は跳ね上がり、新しさによる一時的な伸びにもだまされやすい。対策はシンプルで、始める前に人数と期間を決め、途中でのぞいて止めず、最後に1回だけ判定すること。派手な統計テクニックよりも、この「終わり方を先に決める」という規律のほうが、よほど多くの誤判定を防いでくれます。ランダムに分けて比べる発想そのものは、前回までの実践編や発展編とも地続きです。あわせて読むと、効果検証の勘所が立体的に見えてきます。
A/Bテスト 運用判断チェック
- 問1
あなたが EC のグロース担当で、購入ボタンの色を変える A/Bテスト を 3 日目に確認したところ、新色 (B) の購入率が旧色 (A) より良くなっていました。本記事の主張に従うと、どう判断すべきか?
解説本記事は『差がゼロのテスト』を何千回もシミュレーションし、1 回だけ判定の運用なら誤判定 4.9% だが、毎日のぞいて止める運用では 23.4% (約 5 倍) に跳ね上がったと示しています。「派手な統計テクニックよりも、この『終わり方を先に決める』という規律のほうが、よほど多くの誤判定を防いでくれます」とも整理されています。誤答 (1) はまさに本記事が警告するのぞき見問題、(3) は対照群側を変えるとランダム性が崩れ、(4) は配分を途中で変えるとテスト設計が破綻します。 - 問2
あなたが EC の UI 担当で、現状購入率 3% のサイトで「+5% の改善 (3% → 3.15%)」を見抜きたい A/Bテスト を企画しています。1 日 600 人がアクセスするサイトです。本記事の主張に従うと、何を最初に決めるべきか?
解説本記事は「購入率を3%から3.15%へ、つまり+5%だけ改善したかを見抜くには、1グループあたり約21万人が必要です。1日600人ずつ集まるサイトなら、なんと347日かかる」と明示し、「限られたテスト回数は、効果が大きく出そうな『打ち手の幅が大きい変更』に絞るのが賢明です」と続けています。誤答 (1) はサンプル不足のまま判定し小さな改善を見落とすか偶然の差を拾い、(3) は他社と自社のトラフィックは違い、(4) は誤判定の許容は次の意思決定の土台ごと崩します。 - 問3
あなたが EC の UX 担当で、トップページの新しいバナーを A/Bテスト したところ、初週のクリック率が大幅に伸びました。本記事の主張に従うと、この結果から「効果あり」と本実装してよいか?
解説本記事は「いつも使っている常連が、トップページの新しいバナーに気づいて思わずクリックする。最初の数日はクリック率がぐっと上がりますが、それは『効果』ではなく『目新しさへの一時的な反応』」「曜日による客層のばらつきと、この物珍しさが落ち着くまで、最低でも1〜2週間は回しきってから判断するのが安全」と明示しています。誤答 (1) は新奇効果に騙された早合点、(3) は対照群がないと施策の効果は測れず、(4) はまさにのぞき見で誤判定率を膨らませます。 - 問4
あなたが EC マーケのマネージャーで、「次の A/Bテスト は AI で自動運用にして、有意になった瞬間に勝者を採用する自動化フローを組みたい」という提案が部下から上がりました。本記事の主張に従うと、どう答えるべきか?
解説本記事は「『良くなった瞬間』ではなく『あらかじめ決めた人数・期間』で判断すること」「そもそも何を仮説として立て、何をテストするか。出た結果を自社の文脈でどう読み解き、次の一手にどうつなげるか。ここは人間の仕事として残ります」と整理しています。「有意になった瞬間に止める」自動化はまさにのぞき見問題そのもの。誤答 (1)(4) は自動化で誤判定を量産するリスク、(2) は本記事の主張に真っ向から反します。
データに基づく意思決定を、はてなベースが伴走します
効果検証は「分析の前」が9割です。どのデータを揃え、どんな仮説を立て、何と何を比べるか。ここが整っていないと、どんな高度な手法も誤った結論を出します。はてなベースでは、データに基づく意思決定の土台づくりを支援しています。たとえばこんなケースでお役に立てます。
そのA/Bテスト、正しく回せていますか
散在するデータを集約して分析の土台をつくるデータ基盤の整備、効果検証や仮説設計に伴走する分析・AI活用の支援、そして「全社で安全にAIを使いたい」という方へのオンプレミスAI導入支援まで、貴社の状況に合わせて伴走します。まずは無料相談でお気軽にご相談ください。