Excelで「カテゴリ別に売上を集計して、降順に並べて、総計も出す」──この当たり前の作業を、これまでは SUMIFS を何行も書くか、ピボットテーブルを都度作り直すかで凌いできた方は多いはずです。2024年9月に一般提供が始まった GROUPBY と PIVOTBY という2つの関数は、この集計作業を1行の数式で終わらせるためにMicrosoftが出した「決定打」です。
本記事では、この2つの関数を業務で使いこなすための基礎と、ピボットテーブルとの使い分け、LAMBDA や PERCENTOF を使った応用までを一次情報ベースで整理します。数式が元データに連動するため、月次の作業フロー自体が変わります。筆者の感覚では、これは「便利になった」ではなく「集計の考え方を書き換える関数」です。
SUMIFS は「1セルに1つの集計結果を出す」ための関数。GROUPBY/PIVOTBY は「1つの数式で集計表そのものを返す」ための関数。この設計思想の差が、日々の作業時間の差に直結します。
GROUPBY/PIVOTBY とは何か
ひとことで言うと、GROUPBYはSQLのGROUP BY句を、PIVOTBYはクロス集計をそれぞれExcelの関数として実装したものです。どちらも動的配列関数(1つの数式が複数セルにまたがる結果を返す仕組み)で、元データが変われば自動で再計算されます。
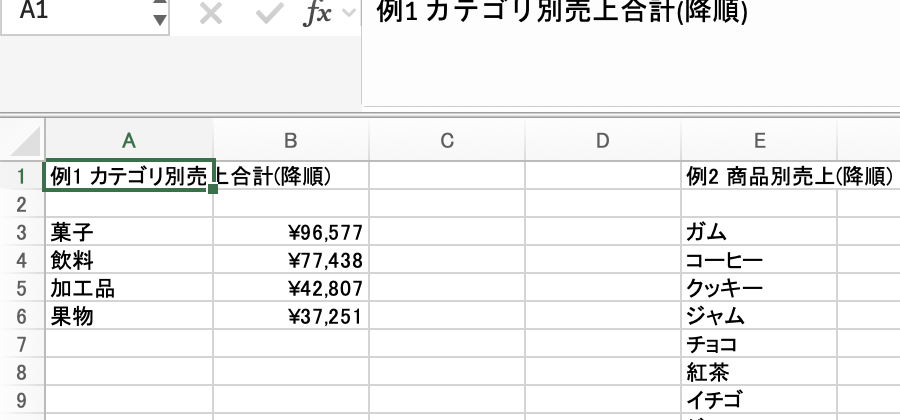
=GROUPBY(売上データ!C2:C51, 売上データ!F2:F51, SUM, 0, 0, -2) と書くだけで、カテゴリ別の売上合計が降順でスピル表示される
従来のピボットテーブルと見た目は似ていますが、中身は全く違います。ピボットテーブルは「静的なオブジェクト」で、元データを変えたら「更新」ボタンを押す必要がありました。GROUPBYは「数式」なので、元データが変わった瞬間に再計算が走ります。他のセルから参照したり、条件付き書式を適用したり、セル単位で値を取り出したり──普通のSUMと同じ感覚で扱えます。
対応環境と前提
使えるかどうかは、Excelのバージョンと契約プランで決まります。2026年4月時点の対応状況を整理しました。
| プラン/バージョン | GROUPBY/PIVOTBY |
|---|---|
| Microsoft 365(Current Channel) | ○(2024年9月GA) |
| Excel 2024(永続版) | ○ |
| Excel 2021(永続版) | ○(2025年アップデート以降) |
| Excel 2019以前 | × |
| Excel for the Web | ○ |
| Excel for Mac | ○ |
| モバイル版(iOS/Android) | ○(表示・編集可) |
組織で半期チャネル(Semi-Annual Enterprise Channel)を使っている場合、配信タイミングが遅れるので注意してください。情シスに確認するか、ヘルプの「バージョン情報」から自社の更新チャネルを確認できます。
構文と引数のクセ
GROUPBY は最大8つ、PIVOTBY は最大11の引数を取りますが、覚えるべきは必須の3〜4つだけです。オプションは必要になったときに調べれば十分です。
GROUPBY の基本形
=GROUPBY(row_fields, values, function, [field_headers], [total_depth], [sort_order], [filter_array])必須は最初の3つ。row_fields がグルーピングに使う列、values が集計対象の列、function が集計方法(SUM・AVERAGE・COUNT・MAX・MIN など)です。
よく使う省略可能引数は total_depth(合計行の出し方。0=なし、1=総計のみ、2=小計+総計、負値=上段配置)と sort_order(並び順。列番号を指定、負値で降順)、そして filter_array(条件フィルタ。ブール配列で行を絞る)の3つです。
PIVOTBY の基本形
=PIVOTBY(row_fields, col_fields, values, function, [field_headers], [row_total_depth], [row_sort_order], [col_total_depth], [col_sort_order], [filter_array], [relative_to])GROUPBYに col_fields が加わってクロス集計になった形、と捉えると理解が早いです。総計や並び順の引数が「行側/列側」で2組に分かれているのが特徴。relative_to は構成比を計算する PERCENTOF と組み合わせたとき、比率の基準軸をどこに置くかを指定する引数です(後述)。
コード例7選(コピペで動く)
自分のデータに合わせて範囲と列名を差し替えれば、そのまま使えるパターンを7つ挙げます。
1. 年別の売上合計(最小構成)
=GROUPBY(A2:A76, D2:D76, SUM)A列が年、D列が売上なら、これだけで「年ごとの売上合計」と「総計」が返ってきます。
2. 商品別・売上降順
=GROUPBY(売上データ!D2:D51, 売上データ!F2:F51, SUM, 0, 0, -2)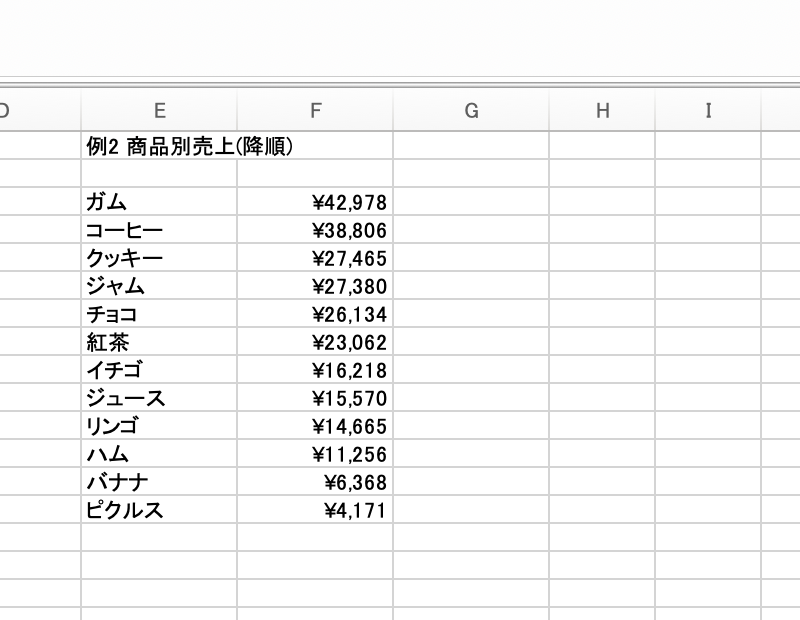
sort_order に -2 を指定すると「売上列で降順」に並ぶ。ガム・コーヒー・クッキー…の順に12商品分が一気に展開される3. 商品×四半期のクロス集計
=PIVOTBY(
売上データ!D2:D51,
"Q"&ROUNDUP(MONTH(売上データ!A2:A51)/3, 0),
売上データ!F2:F51,
SUM, 0, 0, -2, 0)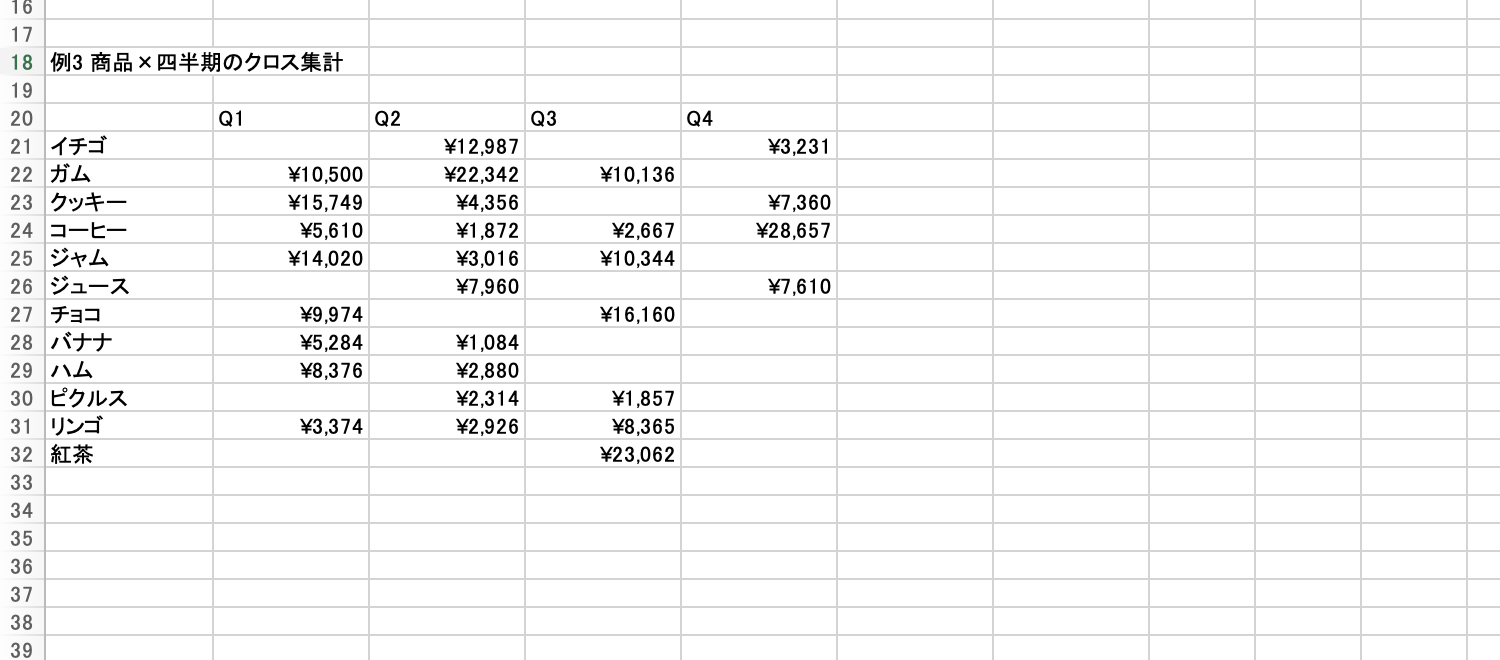
5. 複数の集計値を横に並べる(LAMBDA合成)
=GROUPBY(C2:C76, D2:D76, LAMBDA(v, HSTACK(SUM(v), AVERAGE(v), COUNT(v), MAX(v))))function引数にLAMBDAを渡すことで「合計・平均・件数・最大値を一度に」取得できます。部門別レポートで多用する合わせ技です。
6. 条件フィルタ付き
=GROUPBY(C2:C76, D2:D76, SUM, , , , (A2:A76=2024))filter_arrayに (A2:A76=2024) のような条件配列を渡すと、2024年のデータだけで集計されます。FILTERと組み合わせる必要はありません。
7. テキスト連結(定性データの集約)
=GROUPBY(C2:C76, B2:B76, LAMBDA(x, TEXTJOIN(", ", TRUE, SORT(x))))カテゴリ別に「そのカテゴリに属する商品名をカンマ区切りで並べる」処理。アンケート自由記述の集約や、製品別担当者一覧の作成に便利です。
SUMIFS/ピボットテーブルとの使い分け
「結局、既存のSUMIFSやピボットテーブルと何が違うのか」は実務で一番気になる論点です。特性を整理します。
| 項目 | GROUPBY/PIVOTBY | SUMIFS | ピボットテーブル |
|---|---|---|---|
| 元データ追加時 | 自動再計算 | 範囲指定しなおし要 | 「更新」ボタン操作 |
| 出力形式 | 動的配列 | 1セル1値 | 静的オブジェクト |
| スライサー・フィルタ | 数式で実装 | 不可 | 標準搭載 |
| 数式から参照 | 可(セル参照) | 可 | GETPIVOTDATA経由 |
| 書式の自由度 | 高い | 高い | 中(更新で消えやすい) |
| 数十万行の性能 | △(全走査) | △ | ◎ |
| 学習コスト | 中(引数の順番) | 低 | 中(UI操作) |
使い分けの目安はこうです。日次〜月次の定型レポートにはGROUPBY/PIVOTBYが圧倒的に楽。元データさえ揃えれば、あとはファイルを開くだけで最新値に更新されます。1回ポッキリの探索的な分析にはピボットテーブルが依然強く、ドラッグで軸を入れ替える体験はUIとしてやはり優秀です。SUMIFSは特定のセルに特定の集計値を埋めたいとき──ダッシュボードの「今月の売上」のような単一の値取得用に残ります。
個人的には、毎週作っていた月次集計を全部GROUPBYに置き換えたときの作業時間削減が一番インパクトがありました。ピボットテーブルの更新忘れや範囲拡張のし忘れがなくなり、ファイルを開いた瞬間に正しい数字が見える、という状態はかなり効きます。
応用──LAMBDA・PERCENTOF・BYCOL
基本構文に慣れたら、2026年時点で押さえておきたい発展的な使い方を3つ紹介します。
LAMBDAで独自の集計関数を作る
先ほど5番で紹介した LAMBDA(v, HSTACK(SUM(v), AVERAGE(v), COUNT(v))) のように、function引数には任意のLAMBDAを渡せます。これを使えば「標準偏差も中央値も、四分位も全部」のような独自の集計パックを作れます。名前付き範囲(名前の管理)で StatsPack のような名前を付けておくと、再利用も楽になります。
PERCENTOF で構成比を出す
売上合計の代わりに「全体に占める割合」を出したいとき、function に PERCENTOF を指定します。基準をどこに置くかは relative_to 引数で制御します(0=列総計、1=行総計、2=総計全体、3=親列、4=親行)。
=PIVOTBY(C2:C76, A2:A76, D2:D76, PERCENTOF, , , , , , , 2)これで「全期間・全製品の売上に対する、各製品×各年の構成比」が返ります。経営企画でマーケットシェア分析をするときの定番パターンです。
HSTACK・BYCOL と組み合わせる
Excelの新関数同士は相性が良いので、HSTACK(横結合)、VSTACK(縦結合)、BYCOL(列ごと関数適用)、BYROW(行ごと関数適用)と組み合わせると、集計結果をさらに加工する処理が短く書けます。たとえば複数期間の集計を横に並べたり、集計後にさらに別軸で集計したり、といった合わせ技です。
LAMBDA/HSTACK/BYCOLは覚えるとExcelの書き味が大きく変わる関数群なので、GROUPBYの習得と同時に触れておくと投資効果が高いです。
制限事項と落とし穴
強力な関数ですが、知らずに使うと詰まるポイントもあります。
まず配列サイズの一致。row_fields・values・filter_arrayの行数は一致している必要があります。片方が100行、もう片方が101行だと #VALUE! が返ります。元データがExcelテーブル化されていれば自動的に一致しますが、素の範囲参照で使う場合は注意が必要です。
次にパフォーマンス。数式なので、元データが変わるたびに全件走査が走ります。数十万行規模になると、ピボットテーブルの方が圧倒的に速いケースが出てきます。体感的なしきい値は10万行前後で、それを超える場合は PIVOTBYではなくピボットテーブル、あるいはPower Queryでの前処理を検討するのが妥当です。
そして更新チャネルの違い。Microsoft 365 Apps for Enterprise を半期チャネル(Semi-Annual Enterprise Channel)で運用している企業では、配信が数ヶ月遅れることがあります。管理者側で「月次エンタープライズチャネル」以降に切り替えないと、一部のユーザーだけGROUPBYが使えないという状況になり、共有ファイルのトラブルにつながります。
エラー挙動としては、function に集計関数以外のもの(単なる値を返すLAMBDAなど)を渡すと #CALC! が返ります。また、field_relationship引数は row_fields が複数列のときにしか効きません。このあたりは慣れればエラーメッセージから復旧できますが、最初は戸惑うポイントです。
業務別の使いどころ
具体的な業務シーンでの置き換えアイデアを並べます。自分の部門に近いものから試してみてください。
営業:月次売上レポートを=PIVOTBY(担当者, 商品, 売上, SUM, , , -2)で1行化。元データに新しい行を追加しても、自動で集計が更新されます。従来のSUMIFSマトリクス(行列分の式を書く方式)を一掃できます。
経理:月次試算表を=PIVOTBY(勘定科目, 月, 金額, SUM)で作成。仕訳の追加・訂正が走っても即座に反映されるので、月次締めの手戻りが減ります。外れ値検知と組み合わせるなら前月比の計算列を追加するだけです。
人事:部署別の平均残業時間・人数・合計残業時間を同時に出すレポートに、LAMBDA合成が効きます。=GROUPBY(部署, 残業時間, LAMBDA(x, HSTACK(COUNT(x), AVERAGE(x), SUM(x))))で、1式で全項目を返せます。
マーケティング:キャンペーン別・チャネル別のコンバージョン構成比を、PIVOTBY+PERCENTOFで算出。マーケットシェア分析、ABテスト結果のサマリー、流入経路の寄与率など、構成比を扱う業務に幅広く応用できます。
在庫管理:倉庫別・カテゴリ別の在庫金額をPIVOTBYで一覧化。filter_arrayで「直近30日の入出庫のみ」のような条件を掛ければ、滞留在庫の抽出にもそのまま使えます。
最後に
GROUPBY/PIVOTBYは、集計作業を「関数とピボットテーブルで凌ぐ」時代を静かに終わらせつつあります。すべての集計をこの関数で置き換える必要はないものの、毎週・毎月発生する定型レポートの多くは、確実にこの関数のほうが楽です。
まずは手元の1つのピボットテーブルを選んで、同じ結果を返すGROUPBY/PIVOTBYを1本書いてみてください。元データを変更したときの再計算スピードと、他の数式から参照できる取り回しの良さを体感すると、使い分けの基準が自分の中に自然と生まれます。
Excel新関数の社内展開と分析フロー再設計、はてなベースが伴走します
GROUPBY/PIVOTBYへの置き換え設計、ピボットテーブル依存のレポートの再構築、Power Query/Python in Excelと組み合わせたデータパイプライン整備まで、経理DX事業部がご支援します。オンプレミスでのデータ分析基盤もあわせてご検討可能です。
最終更新 2026.04.23/Excel GROUPBY・PIVOTBY 完全ガイド