2026年5月、「AIはむしろ人間より高くつく」という趣旨の投稿がXで大きな話題になりました(230万回以上の表示)。Microsoftが社内のAIコーディングツール利用を絞り込み、Uberは1年分のAI予算をわずか4か月で使い切った——そうした事例が次々と紹介されています。Fortune をはじめ複数のメディアも、同じ「AIの経済性」の問題を報じています。
ただ、ここから引き出すべき結論は「AIは使えない」ではありません。問題はAIそのものではなく、「AIを入れただけ」で止まっていること、そしてその背景にある データ統合の欠如 です。話題になった投稿を入り口に、何が起きているのか、そして何をすべきかを整理します。
Microsoftは社内のAIコーディングツールの大半のライセンスを縮小し、Uberは1年分のAI予算をわずか4か月で使い切った。トークン課金のもとでは、AIを使うほど請求が膨らみ、置き換えるはずだった人件費を上回ることがある——そんな問題提起が大きな反響を呼んだ。
Ricardo(@Ric_RTP)X・2026年5月24日の投稿より要旨
(話題になった投稿の原文はこちらから確認できます。)
何が起きているのか——「AIの経済性」が問われ始めた
報道や話題の投稿によると、状況はこうです。Microsoftは社内エンジニアに広く開放していたAIコーディングツールについて、大半のライセンスを2026年6月末をめどに縮小し、より安価な自社系のツールへ移すとされています。Uberでは約5,000人のエンジニアが導入し、1人あたり月500〜2,000ドルを消費。半導体メーカーであるNVIDIAの担当役員さえ、自分のチームでは計算資源のコストが従業員のコストをはるかに上回っている、と述べたと報じられています。
用語メモ|トークン課金 — 多くのAIサービスは、処理した文章量(トークン)に応じて料金がかかる仕組みです。つまり「使えば使うほど」「丁寧に何度も使うほど」請求が増えます。人を増やさずに効率化したいはずが、利用が広がるほどコストが膨らむ、という逆転が起こりやすいのはこのためです。
Goldman Sachsは、AIエージェントの普及で2030年までにトークン消費量が24倍に増えると予測しています。たとえ1トークンあたりの単価が下がっても、消費量がそれ以上に増えれば総額は上がります。「AIは安くなる」という直感が、現場の請求書では裏切られているわけです。
用語メモ|AIエージェント — 人間が一手ずつ指示するのではなく、目標を伝えると途中の手順を自分で考えて作業を進めるAIのこと。便利な反面、調べる・試す・直すを自律的に繰り返すため、単純なチャットよりも処理量(=コスト)が一気に増えやすい性質があります。仕組みはAIエージェントとは何かの解説記事で詳しく扱っています。
なぜ「AIを入れただけ」だと、むしろ高くつくのか
コストが膨らむ企業の多くに共通するのが、次のような悪循環です。原因はAIの性能ではなく、AIに渡す「文脈(コンテキスト)」の準備が整っていないことにあります。
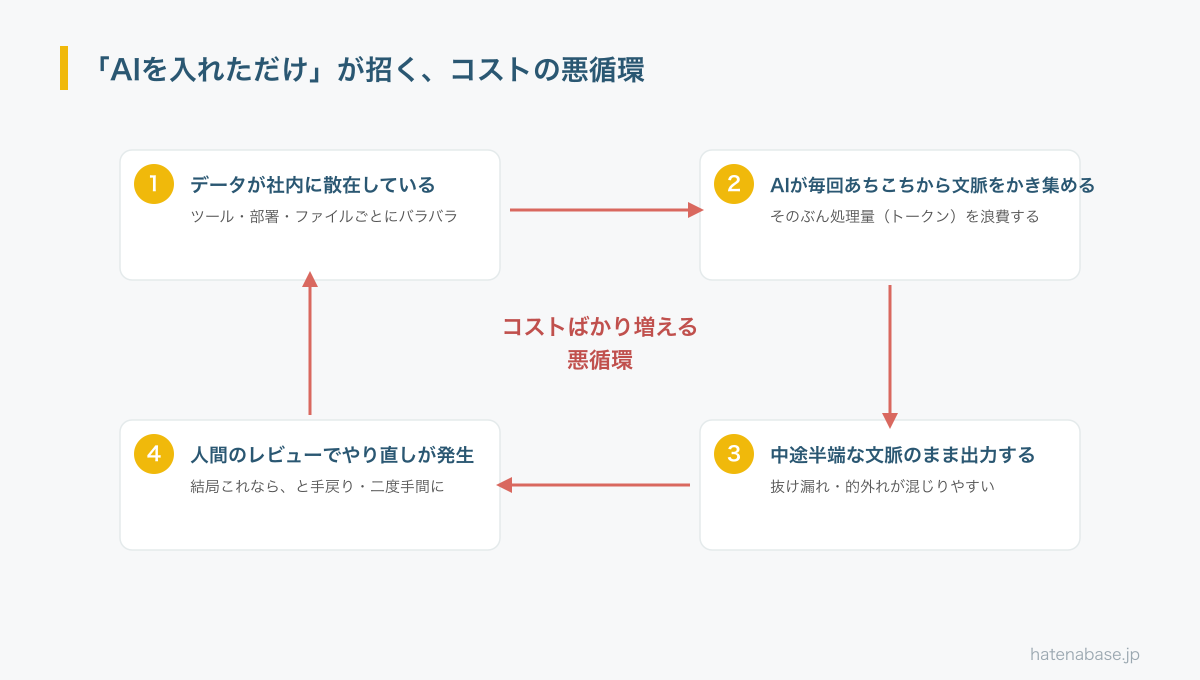
データが部署やツールごとにバラバラだと、AIは答えを出すたびに、あちこちから関連情報をかき集めなければなりません。これがそのまま処理量(トークン)の浪費になります。しかも、集めきれなかった中途半端な文脈のまま出力するため、抜け漏れや的外れが混じります。結果として人間のレビューでやり直しが発生し、「それなら最初から自分でやったほうが早い」という二度手間になります。精緻なものを作ろうとするほど、それぞれが膨大なデータをいろいろな場所から取ってこなければならない——この状態が、コストと手戻りの両方を生んでいるのです。
たとえば、ある問い合わせ対応をAIに任せるとします。顧客情報はCRM、過去のやり取りはメール、契約内容は別の管理表、社内の対応方針はまた別の文書——これらが分かれていると、AIは正確に答えるために毎回それぞれを探して読み込みます。1件あたりの処理量は跳ね上がり、それでも探しきれなければ曖昧な回答になります。担当者はそれを直すために、結局すべての情報源を自分で開いて確認することになり、AIに任せた意味が薄れてしまいます。
つまり、ただAIを導入するだけでは、かえって逆効果になることがあるということです。ツールを配っただけでは、この悪循環はむしろ加速します。AIが高機能であるほど、整っていないデータの海から大量にかき集め、請求書だけが膨らんでいきます。
AI活用には「3つのレイヤー」がある
この悪循環から抜け出すには、AI活用を「段階(レイヤー)」で捉え直すことが有効です。私たちは、AI活用には大きく3つのレイヤーがあると考えています。
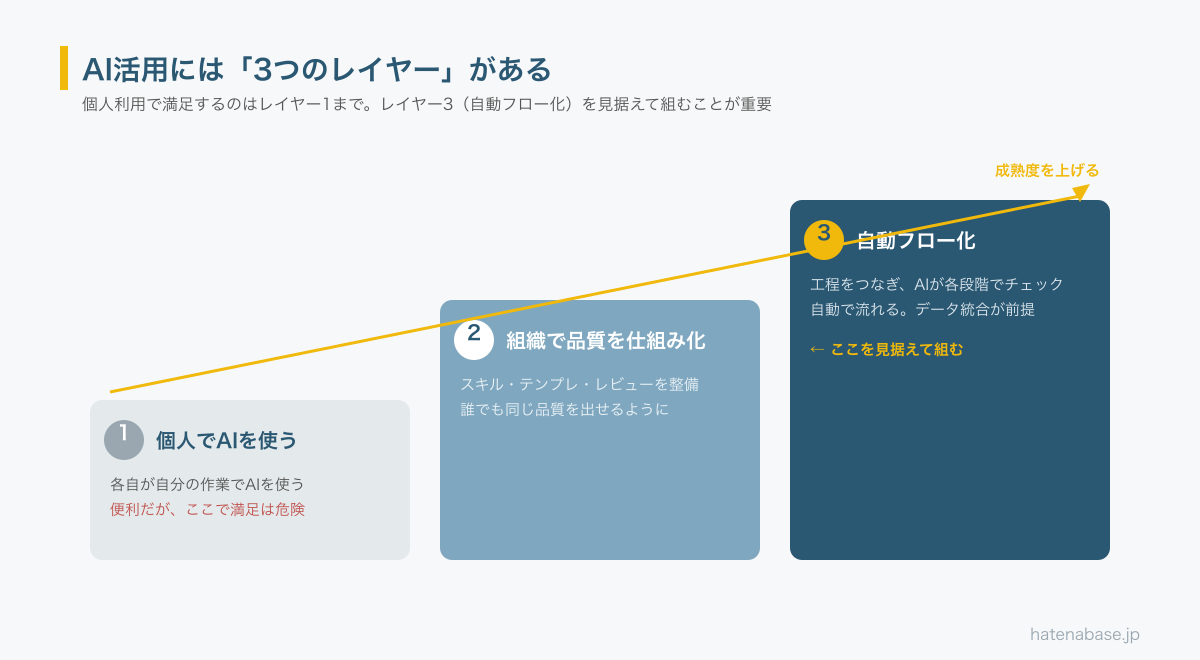
多くの現場は、いまレイヤー1で止まっています。各自が自分の作業でAIを使い、便利だと満足している段階です。これ自体は出発点として良いのですが、ここで止まると、データもフローも整わないまま個人がトークンを消費し、成果物の品質も人によってばらつきます。「個人がAIを使えるようになった」ことと「組織としてAIで成果を出せる」ことは別物です。この壁については『AI導入』の本当の難しさ——個人のスキルでは足りない、フロー管理という壁でも掘り下げています。
レイヤー2は、組織として品質を仕組み化する段階です。よく使う手順をスキルやテンプレートとして整え、誰が使っても同じ品質の成果が出るようにする。レビューの仕組みもそこに組み込み、品質担保を属人芸から仕組みへ移します。再利用できるワークフローをどう作るかはClaude Skillsで再利用可能なワークフローを作る記事が参考になります。
レイヤー1からレイヤー2へ上がれない理由の多くは、「誰かがうまく使えている」状態を組織の標準に落とし込めていないことにあります。優秀な担当者の頭の中にあるプロンプトのコツや確認の勘所を、スキルやチェックリストとして外に出す。これがレイヤー2の核心です。ここを飛ばして自動化(レイヤー3)に進もうとすると、品質のばらつきをそのまま自動で量産することになりかねません。
レイヤー3は、それらを自動フロー化する段階です。工程と工程をつなぎ、AIが各ステップでチェックを担いながら、業務が自動で流れていく状態をつくります。重要なのは、最初からレイヤー3を見据えて組むことです。各人が自分だけでAIを使って満足しているのは、あくまでレイヤー1の話。そこを目的地と勘違いすると、冒頭の悪循環から抜け出せません。
3つのレイヤーを支えるのが「データ統合」
レイヤー1からレイヤー2、レイヤー3へと上がっていくための土台が、データ統合です。スキルやレビューを仕組み化し(レイヤー2)、それを自動で流す(レイヤー3)には、AIが参照すべき情報が一箇所に集約されていることが前提になります。データがバラバラのまま無理にフロー化しても、各工程が毎回データを取りに走るだけで、結局はレイヤー1の悪循環を自動化して固定してしまいます。
逆に言えば、データ統合さえできていれば、AIに渡す文脈が最初から揃います。かき集める無駄が消え、出力の精度が上がり、どこを人がチェックすべきかも明確になります。データ統合は地味な作業に見えますが、AI時代においては「AIを安く・確実に動かすための前提条件」そのものなのです。
データ統合がAIを「安く・確実」にする4つの効果
データ統合ができていると、AI活用のフローは具体的に次のように変わります。
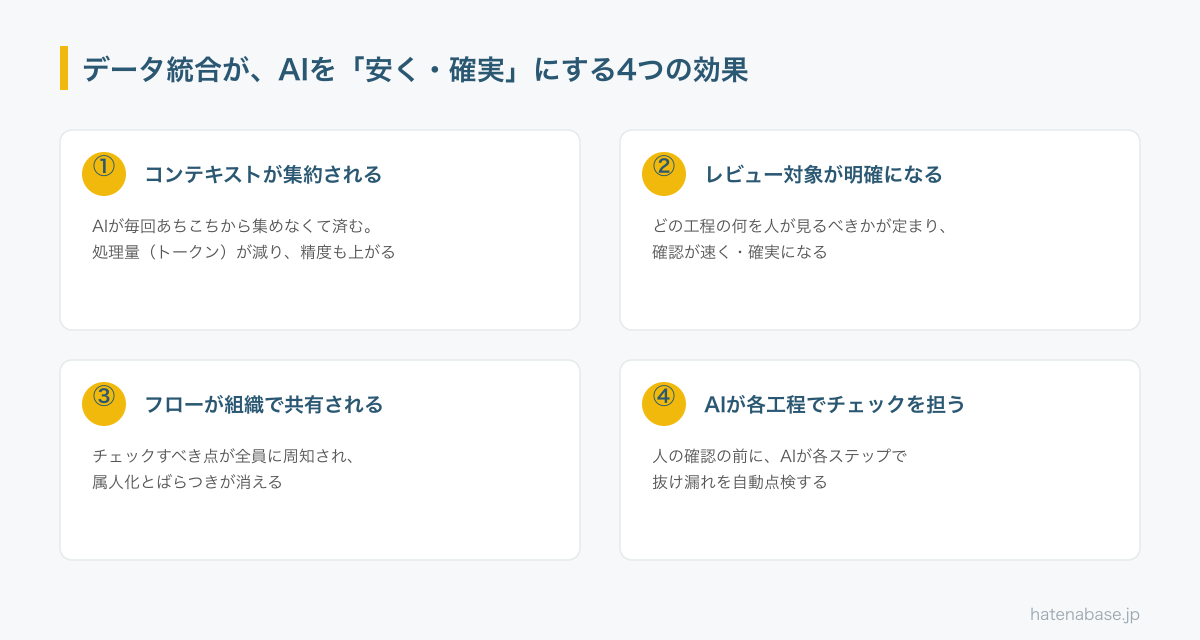
- コンテキストが集約される — AIが毎回あちこちから情報をかき集める必要がなくなり、処理量(トークン)が減ってコストが下がる。同時に、揃った文脈で答えるため出力の精度も上がる。
- レビューすべき対象が明確になる — どの工程の、何を、人が確認すべきかが定まる。漠然と全体を見直す必要がなくなり、レビューが速く確実になる。
- フローが組織全体で共有される — チェックすべきポイントが全員に周知され、品質が属人化せず、担当が変わっても同じ基準で回る。
- AIが各工程でチェックを担う — 人が確認する前に、AIが各ステップで抜け漏れや矛盾を自動点検する。人とAIの二段構えで、手戻りそのものを減らせる。
この4つは、いずれも冒頭の悪循環を逆回しにするものです。かき集めの無駄を消し、中途半端な出力を防ぎ、やり直しを未然に止める。データ統合は「コストを下げる」と「品質を担保する」を同時に実現する、数少ない打ち手なのです。業務をこのように適切にフロー化していくためにこそ、データ統合が必要になります。逆に、それができていないからこそ、いま各社で起きているようなコストの問題が生まれているとも言えます。
「AIを見据えたデータ統合」への原点回帰
データ統合の重要性は、実は以前から語られてきました。それでも「地味で、すぐに効果が見えにくい」ために後回しにされ、その価値はなかなか伝わりにくいテーマでもあります。しかし、今回のように「AIのほうが人件費より高くついた」という具体的な事例が出てくると、話は変わります。データ統合の重要性が、はじめて生々しい数字とともに突きつけられるからです。
ここで必要なのは、原点回帰です。流行りのツールを次々に試す前に、もう一度データ統合に立ち返り、それを意識的に強めていく。しかも、ただ統合するのではなく、AIを見据えた形で作ることが肝心です。AIが参照しやすいように整理し、構造化し、フローの各工程から呼び出せるようにしておく。こうして初めて、レイヤー3の自動フロー化が現実のものになります。「AIを入れる」より先に「AIが使えるデータを整える」。この順序を逆にすると、高機能なAIほど高くつきます。生成AIを組織で安全に回す体制づくりは中小企業のための生成AI運用ルール整備ガイドもあわせてご覧ください。
「AIを見据えたデータ統合」とは、具体的には地道な整備の積み重ねです。用語や項目名の表記を揃える、どこに何があるかを説明情報(メタデータ)として持たせる、アクセス権を整理してAIが安全に参照できる範囲を決める。こうした足場があってはじめて、AIは少ない処理量で正確に答えられ、各工程に安心して組み込めるようになります。派手さはありませんが、ここがAI活用の投資対効果を最も左右する部分です。
「とりあえずAIを導入する」が先に来ると、散在したデータの上でAIがトークンを浪費し、レビューでのやり直しも増えて、むしろコストが膨らみます。順序は逆です。AIを見据えてデータを統合し、業務をフロー化したうえでAIを各工程に組み込む。これが、AIを逆効果にしないための鉄則です。
まとめ|問われているのは「AIの限界」ではなく「入れただけの限界」
話題の投稿が示したのは、AIの限界ではありません。データ統合もフロー設計もないまま「AIを入れただけ」で止まることの限界です。AI活用を3つのレイヤーで捉え、レイヤー3(自動フロー化)を見据えて組む。その土台として、AIを見据えたデータ統合に原点回帰する。これができている組織では、AIはコストを下げ、品質を底上げする味方になります。できていない組織では、同じAIが請求書を膨らませる重荷になります。
分かれ目は、AIそのものではありません。AIに渡すデータと、その流れをどこまで整えられているか。いま一度、自社のデータがAIを動かせる状態になっているかを点検することが、これからのAI活用の出発点になります。
はてなベースは、「AIを入れたのに効果が出ない・むしろ高くつく」を、その手前のデータ統合から立て直すご支援をしています。AIを見据えた社内データの統合・整理という土台づくりから、業務フローへのAIエージェントの組み込み設計、そして「全社で使いたいがセキュリティが心配」という企業向けのオンプレミス環境での生成AI導入まで。レイヤー1の個人利用から、レイヤー3の自動フロー化へ——段階を踏んだ伴走が得意です。