ついにClaude超え? ベンチマーク14項目の結果を徹底検証
Terminal-Bench 82.7% / トークン効率40%改善 / ただしハルシネーション率86%の落とし穴も。2026年4月23日にOpenAIが発表した最新モデル「GPT-5.5」の全貌を、ベンチマーク数値・API料金・利用プラン別の違い・競合モデルとの比較まで網羅的に整理しました。ChatGPTユーザーにも、API開発者にも、AI導入を検討中の企業担当者にも役立つ内容です。
GPT-5.5の概要 — 何が変わったのか
2026年4月23日、OpenAIは最新のフラッグシップモデル「GPT-5.5」(開発コードネーム「Spud」)を発表しました。前モデルGPT-5.4の発表からわずか6週間という異例のスピードでのリリースです。
GPT-5.5は、GPT-5.1〜5.4のような増分アップデートとは根本的に異なります。GPT-4.5以来となるフルスクラッチの基盤モデル再学習を行った初めてのモデルであり、テキスト・画像・音声・動画を単一のシステムで処理するネイティブ・オムニモーダル設計が採用されています。
GPT-5.5の主なスペック
- コンテキストウィンドウ — 100万トークン(API)/ 40万トークン(Codex)
- 最大出力トークン — 128,000トークン
- マルチモーダル入力 — テキスト、画像、音声、動画に対応
- エージェント型タスク設計 — マルチツール連携を前提としたアーキテクチャ
- 学習完了日 — 2026年3月24日
OpenAI社長のGreg Brockman氏は記者発表で「GPT-5.5は新しいクラスの知性であり、より直感的でエージェント型のコンピューティングに向けた大きな一歩」と述べています。
GPT-5.5の3つのバリエーション
GPT-5.5には用途の異なる3つのバリエーションが用意されています。
| モデル | 特徴 | 利用可能プラン |
|---|---|---|
| GPT-5.5 | 標準モデル。コーディング、リサーチ、データ分析など汎用タスク向け | Plus / Pro / Business / Enterprise |
| GPT-5.5 Thinking | 推論(Reasoning)特化モード。複雑な論理・数学・科学的分析に強い | API経由で推論レベル調整可能 |
| GPT-5.5 Pro | 最高性能バリエーション。ブラウジング性能90.1%達成 | Pro / Business / Enterprise のみ |
API利用時には推論の深さを5段階(xhigh / high / medium / low / non-reasoning)で調整できます。タスクに応じて「考える深さ」をコントロールすることで、スピードとコストのバランスを最適化できるのが新しいポイントです。
ベンチマークで見る性能 — 14項目の評価結果
OpenAIはGPT-5.5の発表に合わせて、複数のベンチマーク結果を公開しました。特にコーディングとエージェント型タスクで目立つ成績を収めています。
| ベンチマーク | GPT-5.5 | GPT-5.4 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | — | 69.4% | 68.5% |
| Expert-SWE(内部評価) | 73.1% | 68.5% | — | — |
| SWE-Bench Pro | 58.6% | — | 64.3% | — |
| GDPval | 84.9% | — | 80.3% | 67.3% |
| OSWorld-Verified(PC操作) | 78.7% | — | 78.0% | — |
| FrontierMath Tier 4 | 35.4% | — | 22.9% | 16.7% |
| FrontierMath Tier 1-3 | 51.7% | — | 43.8% | — |
| CyberGym | 81.8% | — | 73.1% | — |
| Tau2-Bench Telecom | 98.0% | — | — | — |
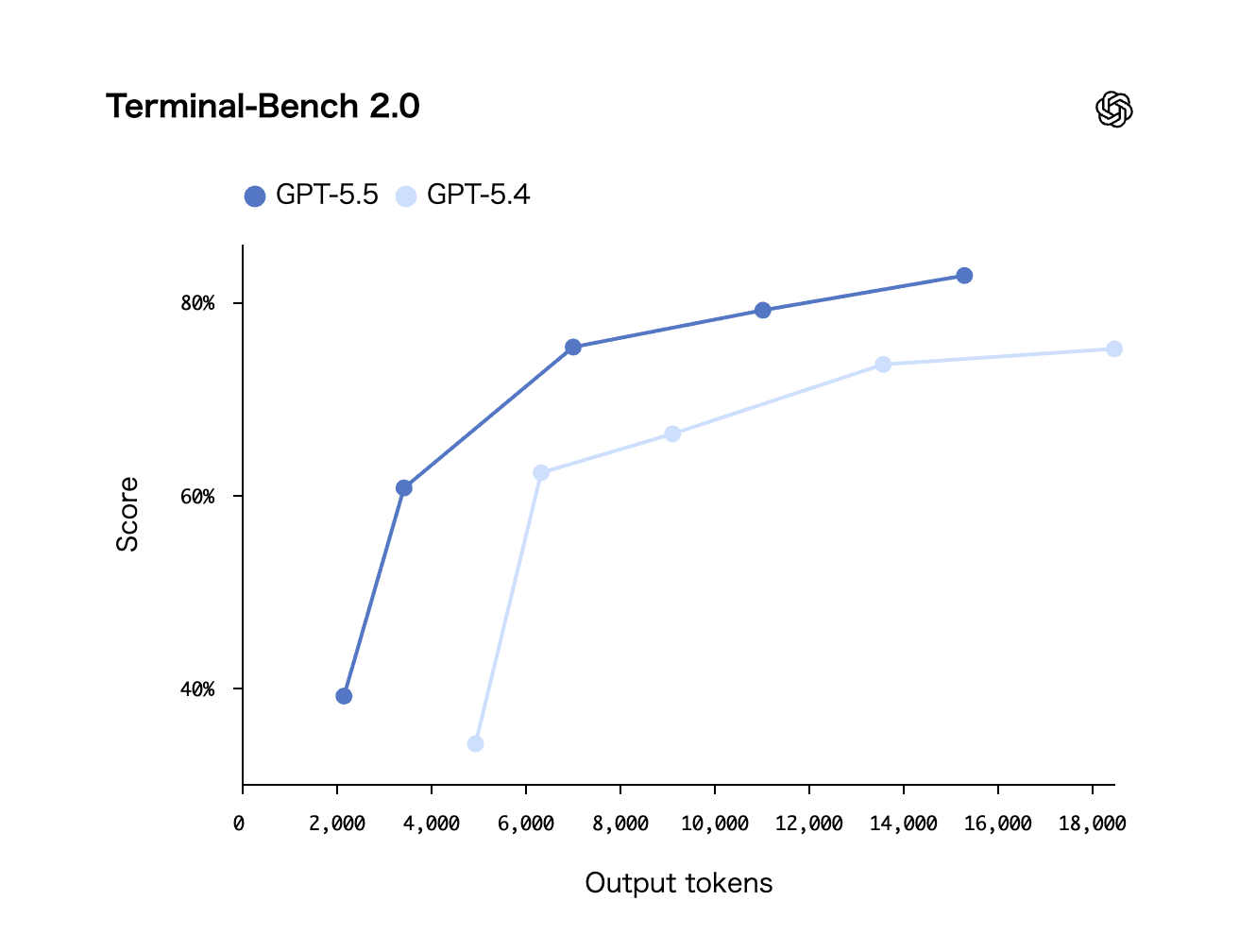
Terminal-Bench 2.0 — コーディング性能で圧倒
最も注目すべきはTerminal-Bench 2.0のスコアです。GPT-5.5は82.7%を記録し、Claude Opus 4.7(69.4%)やGemini 3.1 Pro(68.5%)に対して13ポイント以上の差をつけました。ターミナル環境でのコード実行・デバッグといった実践的なコーディングタスクで、現時点で最も高い性能を示しています。
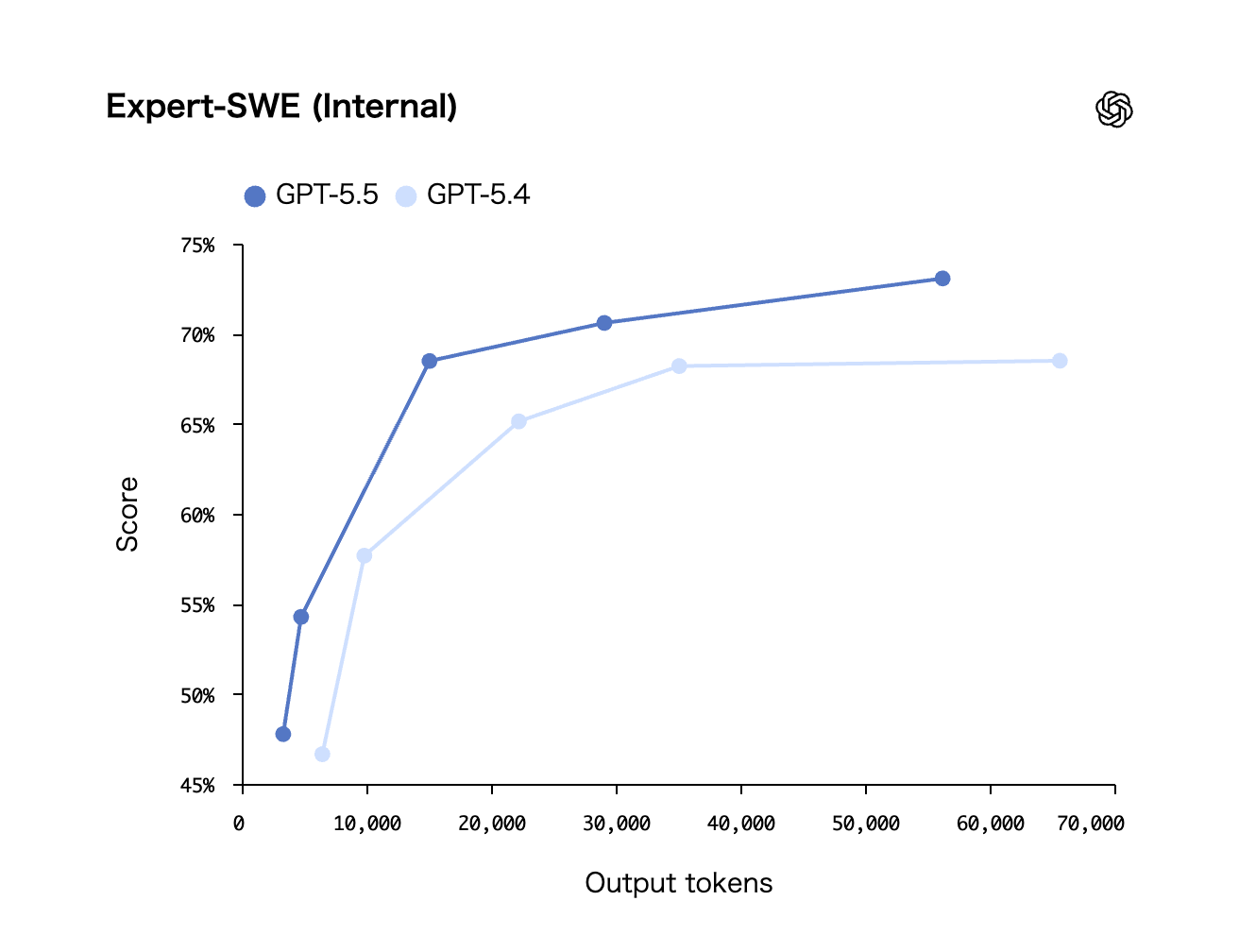
Expert-SWE — 新設の高難度コーディング評価
Expert-SWEはGPT-5.5の発表に合わせてOpenAIが新設した内部ベンチマークで、完了までの中央値が20時間という高難度タスクで構成されています。GPT-5.5は73.1%を記録し、GPT-5.4の68.5%から約5ポイント改善しました。
FrontierMath — 数学研究で圧倒的な差
FrontierMath Tier 4は最先端の数学問題を含むベンチマークです。GPT-5.5の35.4%はClaude Opus 4.7(22.9%)の約1.5倍、Gemini 3.1 Pro(16.7%)の約2倍のスコアです。OpenAIによれば、GPT-5.5のカスタムバリアントがラムゼー数に関する新しい証明を発見し、数学の証明検証言語Leanで検証済みとのことです。
SWE-Bench Pro — Claude Opus 4.7が優勢
一方、SWE-Bench ProではClaude Opus 4.7が64.3%でGPT-5.5の58.6%を上回っています。実際のオープンソースプロジェクトのバグ修正タスクにおいては、Claudeの方が高い解決率を示しています。
ベンチマーク結果を見る際の注意点
Expert-SWEはOpenAI内部で設計されたベンチマークであり、他社モデルとの直接比較データはまだ公開されていません。公平な比較には、SWE-Bench Proのような第三者が管理するベンチマークのスコアを重視することをおすすめします。
Artificial Analysisのインテリジェンス指標による比較
独立評価機関Artificial Analysisが公開しているインテリジェンス指標では、GPT-5.5は出力トークンの量に応じた総合的な知能スコアで全モデル中トップを記録しています。
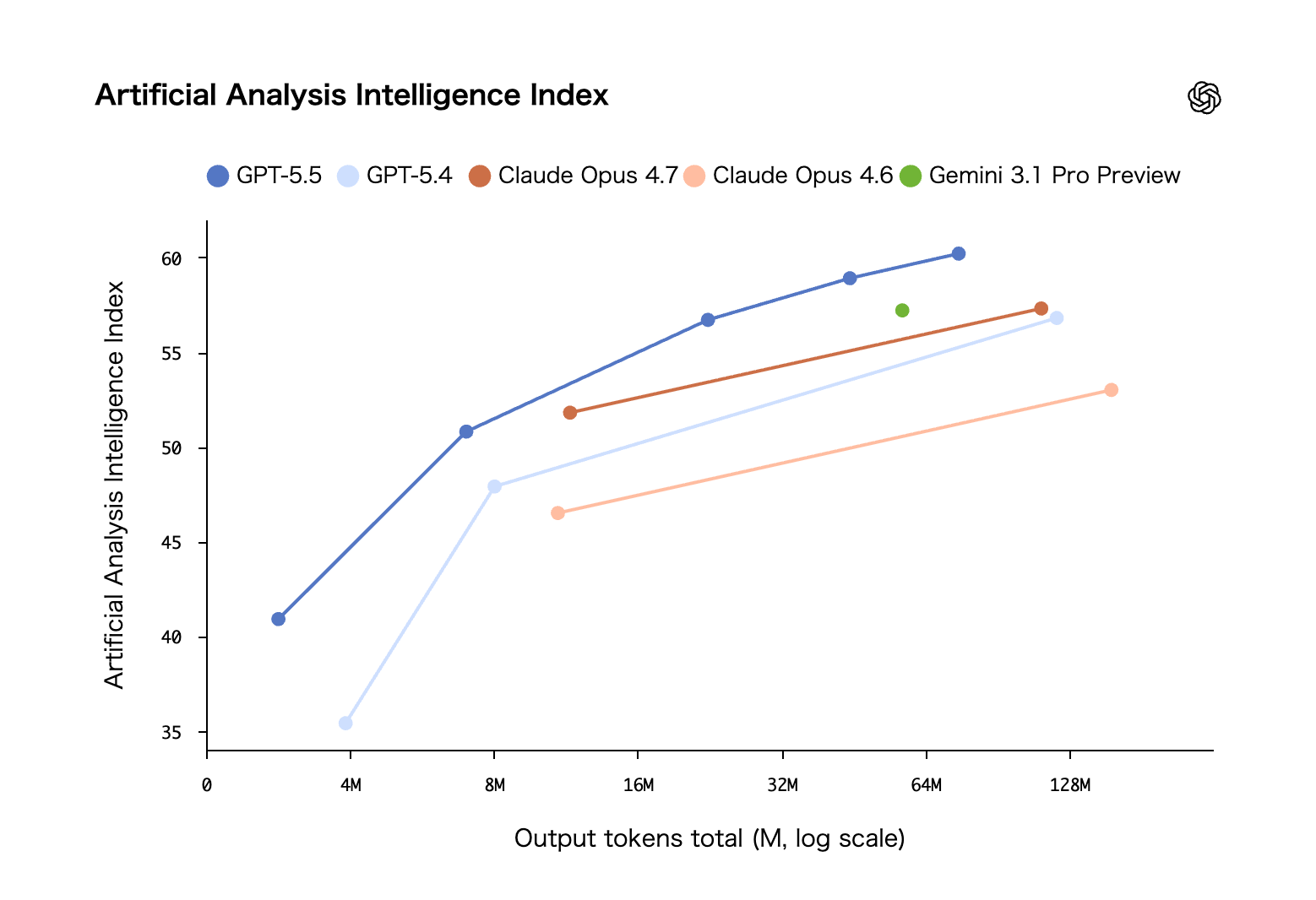
このグラフから読み取れるポイントを整理します。
グラフの読み方
- GPT-5.5(濃い青)が全出力トークン帯で最高スコア。64Mトークン時点で約60.5を記録
- Claude Opus 4.7(濃いオレンジ)は128Mトークン帯で約57.5。GPT-5.5との差は約3ポイント
- GPT-5.4(薄い青)はClaude Opus 4.7と同水準で推移
- Gemini 3.1 Pro Preview(緑)は64Mトークン帯で単一データポイントのみ公開。約57.5
- Claude Opus 4.6(薄いオレンジ)は128Mトークン帯で約53。世代間の進化幅が大きい
特筆すべきは、GPT-5.5が少ないトークン出力でも高いスコアを達成している点です。4Mトークン時点ですでに約41に達しており、同じトークン量でのGPT-5.4(約35)やClaude Opus 4.6(約35)を大きく引き離しています。これは後述する「トークン効率の40%改善」を裏付ける結果です。
API料金とコスト比較
GPT-5.5のAPI料金は前世代から引き上げられました。ただしトークン効率の改善により、タスクあたりの実質コストは抑えられる設計です。
| モデル | 入力(100万トークンあたり) | 出力(100万トークンあたり) | 備考 |
|---|---|---|---|
| GPT-5.5 | $5.00 | $30.00 | GPT-5.4の2倍 |
| GPT-5.5 Pro | $30.00 | $180.00 | GPT-5.4 Proと同額 |
| GPT-5.4(参考) | $2.50 | $15.00 | — |
| Batch / Flex | 標準の50%割引 | 標準の50%割引 | 非同期処理向け |
| Priority | 標準の2.5倍 | 標準の2.5倍 | Codexで1.5倍速 |
コスト効率の考え方
単価だけ見るとGPT-5.4の2倍に思えますが、OpenAIの発表によれば、同じCodexタスクで出力トークンが約40%削減されるため、実際のコスト増は2倍ではなく約1.2倍程度に収まるケースが多いとしています。
コスト試算の例
あるコーディングタスクで、GPT-5.4が10,000出力トークン必要だった場合、GPT-5.5では約6,000トークンで同じ結果を得られます。
- GPT-5.4のコスト = 10,000 × $15 / 1M = $0.15
- GPT-5.5のコスト = 6,000 × $30 / 1M = $0.18
単価は2倍でも、実コストは約20%増に留まります。品質が高い回答を一発で得られる場面では、リトライ削減によりむしろコスト減になる可能性もあります。
ChatGPTでの利用プランと使い方
GPT-5.5はChatGPTの有料プランで即日利用可能になっています。
| プラン | 月額 | GPT-5.5 | GPT-5.5 Pro | Codex |
|---|---|---|---|---|
| Free | 無料 | ✕ | ✕ | ✕ |
| Plus | $20/月 | ○ | ✕ | ○ |
| Pro | $200/月 | ○ | ○ | ○ |
| Business | $25/ユーザー/月 | ○ | ○ | ○ |
| Enterprise | 要問い合わせ | ○ | ○ | ○ |
ChatGPTでの使い方
ChatGPTのモデル選択メニューから「GPT-5.5」を選ぶだけで利用開始できます。特別な設定は不要です。GPT-5.5 Proを使いたい場合は、Proプラン以上への加入が必要です。
GPT-5.5が得意とするタスクには以下のようなものがあります。
- コードの作成・デバッグ — 大規模なシステム全体の文脈を保持しながら、曖昧な障害を推論できる
- オンラインリサーチ — Webを横断して情報を収集・整理
- データ分析 — スプレッドシートやCSVの読み込みと分析
- ドキュメント作成 — ビジネス文書、レポートの下書き
- ソフトウェア操作 — Codexと連携してPC上のアプリケーションを操作
ChatGPT利用者数の最新動向
2026年4月時点のOpenAI公式発表データでは、Codexのアクティブユーザーが400万人、ビジネス有料ユーザーが900万人に到達しています。
GPT-5.4からの改善点
GPT-5.5はGPT-5.4から6週間で発表されましたが、増分アップデートではなく、基盤モデルのフルスクラッチ再学習を行っています。主な改善点を整理します。
GPT-5.5の主な進化ポイント
- トークン効率が約40%改善 — 同じCodexタスクで、GPT-5.4よりも40%少ないトークンで完了。「より少ない言葉で、より的確な回答」を実現
- コンピュータ操作がClaude Opus 4.7と同水準に — OSWorld-Verifiedで78.7%を達成(Claudeは78.0%)。デスクトップ操作の自動化でほぼ互角
- 曖昧な指示からの計画立案能力 — 「ビジネス上のまとまりのない要求を整理して、実行可能な計画に落とし込む」能力が大幅に向上
- レイテンシは維持 — 性能向上にもかかわらず、応答速度はGPT-5.4と同等レベルを維持
- ネイティブ・オムニモーダル — テキスト・画像・音声・動画を単一アーキテクチャで処理(GPT-5.4は個別処理)
Bank of New York(BNY)のCIOは「印象的なハルシネーション耐性」と評価し、特に規制産業のように高い精度が求められる場面での性能向上を「ステップチェンジ」と表現しています。
また、ある教授がGPT-5.5に対して単一のプロンプトから代数幾何学のアプリケーションを生成させたところ、わずか11分で完成したというデモも紹介されています。
競合モデルとの比較 — Claude Opus 4.7・Gemini 3.1 Pro
GPT-5.5の発表に合わせて、OpenAIは主要な競合モデルとの性能比較データを公開しています。ここでは各モデルの強みと弱みを整理します。
総合ポジショニング
| 項目 | GPT-5.5 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|
| コンテキストウィンドウ | 100万トークン | 100万トークン | 100万トークン |
| 最大出力トークン | 128,000 | 128,000 | — |
| コーディング(Terminal-Bench) | 82.7% | 69.4% | 68.5% |
| バグ修正(SWE-Bench Pro) | 58.6% | 64.3% | — |
| PC操作(OSWorld) | 78.7% | 78.0% | — |
| 数学(FrontierMath T4) | 35.4% | 22.9% | 16.7% |
| ブラウジング(Pro版) | 90.1% | 79.3% | — |
| API入力料金 | $5 / 1M | — | — |
| API出力料金 | $30 / 1M | — | — |
GPT-5.5が優勢な領域
- コーディング全般 — Terminal-Bench 2.0で13ポイント以上の大差。コード生成・デバッグの一貫性が高い
- 数学・科学 — FrontierMathで他モデルの1.5〜2倍のスコア。研究レベルの数学問題に強い
- ブラウジング — Pro版の90.1%はClaude Opus 4.7の79.3%を大幅に上回る
- エージェント型タスク — CyberGymやTau2-Benchでも高スコア
Claude Opus 4.7が優勢な領域
- 実プロジェクトのバグ修正 — SWE-Bench Proで64.3% vs 58.6%。実務に近いコーディングタスクではClaude優位
- リサーチライティング — 論文調の文章生成や指示追従性でClaude Opus 4.7が高く評価されている
- 画像認識の解像度 — ビジョン入力の精度でもClaude Opus 4.7に優位性がある
- ハルシネーション耐性 — 後述するが、GPT-5.5のハルシネーション率は課題が指摘されている
Gemini 3.1 Proの位置づけ
Gemini 3.1 Pro PreviewはArtificial Analysisのインテリジェンス指標で約57.5を記録しており、GPT-5.4やClaude Opus 4.7と同水準です。Googleのエコシステム(Workspace、Cloud)との統合が強みですが、エージェント型タスクのベンチマークはまだ限定的な公開にとどまっています。
注意すべき課題 — ハルシネーション率の問題
GPT-5.5は多くのベンチマークでトップクラスの性能を示しましたが、ハルシネーション(事実と異なる回答を自信を持って生成する問題)については重要な課題が指摘されています。以下のデータは、AIモデルの性能を独立的に評価する第三者機関「Artificial Analysis」が公開した「AA-Omniscience」テストの結果です(2026年4月時点)。
Artificial Analysis「AA-Omniscience」テストの結果
AA-Omniscienceは、モデルが「知っていること」と「知らないことを認められるか」を同時に測定するテストです。GPT-5.5(xhighモード)は正答率57%で全モデル中最高でしたが、「知らないはずの質問にも自信を持って回答してしまう」割合、すなわちハルシネーション率が86%と報告されました。
- GPT-5.5(xhigh) — 正答率57%、ハルシネーション率86%
- Claude Opus 4.7(max) — ハルシネーション率36%
- Gemini 3.1 Pro Preview — ハルシネーション率50%
この数値は「知識を多く引き出せるが、その分だけ誤った情報を自信を持って出力してしまう確率も高い」というトレードオフを示しています。つまり、GPT-5.5はより多くのことを「知っている」が、その知識が正しいかの確認が他モデル以上に重要です。
実務への影響
この特性から、以下のような使い分けが推奨されます。
| 用途 | GPT-5.5の適性 | 推奨 |
|---|---|---|
| コード生成・デバッグ | 非常に高い | コンパイラやテストが正誤を検証するため、ハルシネーションの影響が小さい |
| 数学・科学計算 | 非常に高い | 形式検証(Leanなど)との併用で信頼性を担保 |
| ドラフト文書・ブレスト | 高い | 下書き生成には最適。最終確認は人間が行う |
| 事実確認が必須の業務 | 要注意 | 法務・医療・財務レポートなどでは必ずファクトチェックを挟む |
| 顧客対応のチャットボット | 要注意 | 誤情報リスクが直接的な損害につながるため慎重な設計が必要 |
企業での活用シーンと導入判断のポイント
GPT-5.5は「エージェント型コンピューティング」を強く志向しています。単にテキストを生成するだけでなく、複数のツールを横断してタスクを完了する能力が重視されています。企業のAI導入においてどのような場面で活きるかを整理します。
GPT-5.5が特に力を発揮するシーン
開発チームのコーディング支援
Codexと連携し、「大規模なシステム全体のコンテキストを保持したまま、曖昧な不具合の原因を推論し、ツールを使って仮説を検証する」というワークフローが可能です。Terminal-Benchのスコアが示す通り、ターミナル環境でのデバッグ能力は現状最高レベルです。
業務データの分析とレポート作成
100万トークンのコンテキストウィンドウにより、大量のCSVやExcelデータを一度に読み込んで分析し、レポートにまとめるタスクに適しています。「散らばったビジネス要件を整理して実行計画に落とし込む」能力も向上しています。
ソフトウェア操作の自動化
OSWorld-Verifiedで78.7%を達成しており、PC画面の読み取りと操作を伴う業務自動化に使えます。定型的な管理画面操作やデータ入力作業の自動化に向いています。
導入判断のチェックポイント
- 現在GPT-5.4を使っているか — Codexのヘビーユーザーであれば、トークン効率40%改善の恩恵が大きい
- コスト感度 — API単価は2倍。Batch/Flex割引(50%オフ)を活用できるかで判断が変わる
- 正確性の要件 — 事実確認が最重要のユースケースでは、ハルシネーション率の高さを考慮してClaude Opus 4.7との併用や検証レイヤーの導入を検討
- APIの提供時期 — 発表時点ではAPIは「Coming very soon」のステータス。Cursor、Windsurf、Vercel AI Gateway、OpenRouterなどのパートナーへの展開も予定されている
まとめ
GPT-5.5は、GPT-4.5以来の基盤モデル再学習を経た「世代交代」モデルです。コーディング、数学、エージェント型タスクではベンチマーク最高水準を達成しており、特にCodexユーザーにとってはトークン効率40%改善という実利が大きいアップデートです。
一方で、ハルシネーション率86%という数値は無視できない課題です。「知識量が増えた分、誤りの自信度も上がった」という構造的な問題を抱えており、事実確認が求められる業務では追加の検証が欠かせません。
AI活用の選択肢が広がる中、重要なのは「どのモデルが最強か」ではなく、自社のユースケースに合ったモデルを選ぶことです。コーディング重視ならGPT-5.5、正確性重視ならClaude Opus 4.7、Googleエコシステム連携ならGemini 3.1 Proと、それぞれの強みを理解した上で最適な組み合わせを検討してみてください。