2026年5月18日、NVIDIAはAnthropicとOpenAI、SpaceXAIへ「Vera CPU」の初出荷を完了した。2日後の20日にはOracle Cloud Infrastructure(OCI)にも届けられた。GPU(画像処理半導体)の世界覇者として知られるNVIDIAが、なぜ今CPUを独自開発するのか。その答えは「AIエージェント」にある。
AIエージェントとは、単純な質問への回答を超えて、複数のツールを呼び出しながら自律的にタスクを実行するAIシステムのことだ。コードを書き、検索し、外部サービスと連携し、判断を重ねながら目標を達成する。こうした処理には、GPUとは異なる種類の演算が大量に発生する。オーケストレーション(複数エージェントの調整)、ツール呼び出し、サンドボックス実行(安全な隔離環境)、長い文脈の検索などがその代表だ。従来のx86系CPUはこれらに最適化されておらず、AIファクトリーの「ボトルネック」になっていた。Vera CPUはそのボトルネックを正面から解決するために生まれた、初のCPUである。
Ian Buckが語るVera CPUの意義
「AIエージェント時代は、AIファクトリーに新たなCPUの瞬間をもたらしている。モデルが答えることから行動することへと移行するにつれ、Veraはその作業をスケールで動かし続けるために作られた」 — NVIDIA バイスプレジデント Ian Buck
Vera CPUの主要スペックと性能比較
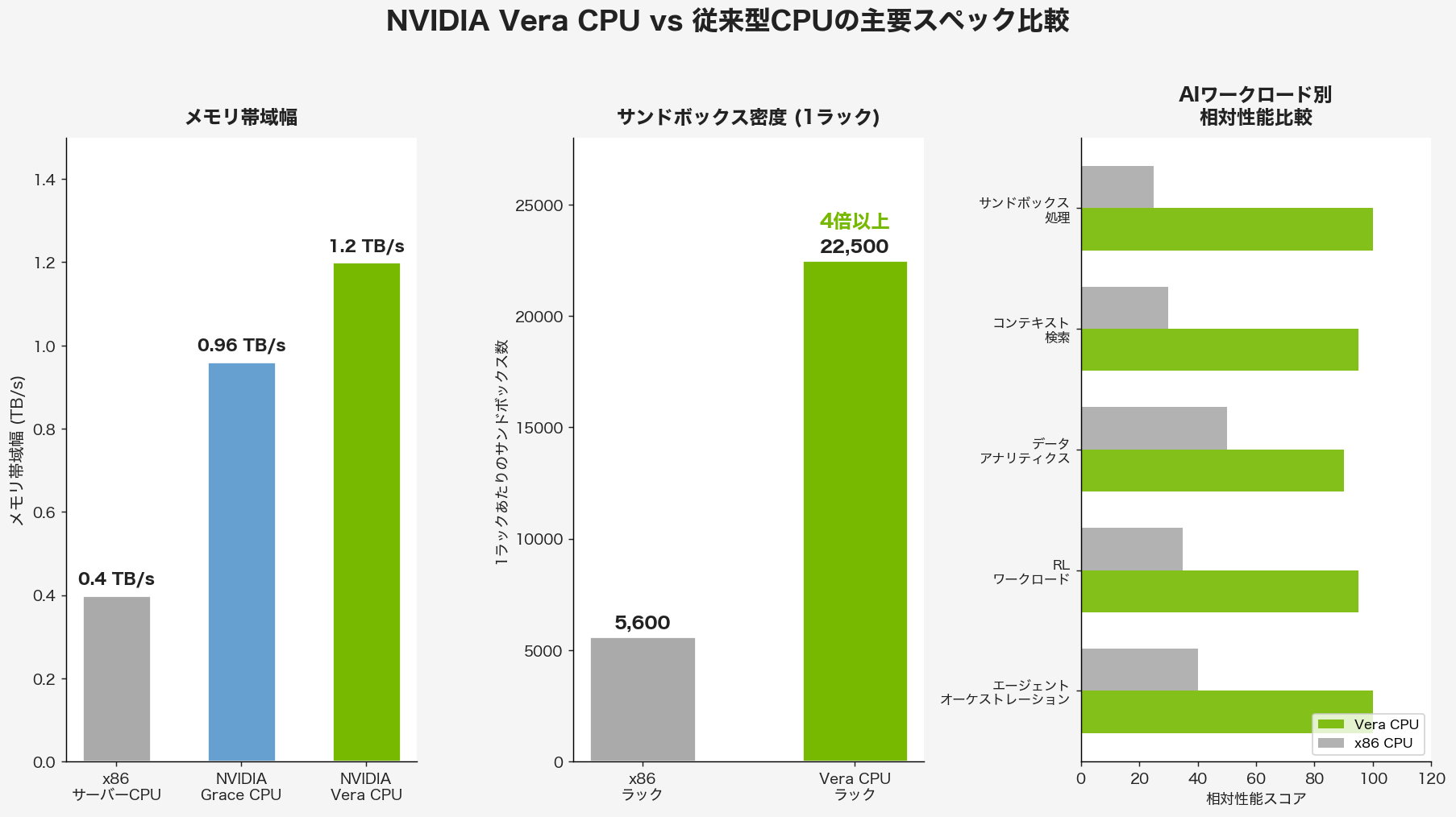
上のグラフが示す通り、Vera CPUのスペックは従来のサーバー向けCPUを大幅に上回る。特にメモリ帯域幅と、AIエージェントが必要とするサンドボックス処理密度において圧倒的な差がある。以下の表でより詳細に見ていこう。
| スペック項目 | x86系サーバーCPU(比較基準) | NVIDIA Grace CPU | NVIDIA Vera CPU |
|---|---|---|---|
| カスタムコア | なし(既存Armライセンス) | Arm Neoverse V2(72コア) | Olympusコア(88コア) |
| メモリ帯域幅 | 約400 GB/s | 約960 GB/s | 1.2 TB/s(14 GB/s/コア) |
| 1ラックのサンドボックス密度 | 約5,600 | — | 22,500以上(4倍超) |
| 電力効率(サンドボックス) | 基準 | — | x86比 2倍のperformance per watt |
| メモリ容量(最大) | 標準DDR | — | 1ソケットあたり最大1.5 TB |
| GPU連携インターフェース | PCIe | NVLink-C2C 第1世代 | NVLink-C2C 第2世代(1.8 TB/s) |
| AIエージェント向け最適化 | なし | 部分的 | 専用設計(Spatial Multithreading) |
特筆すべきは1ラックあたりのサンドボックス数だ。x86ベースのラックが最大5,600程度のサンドボックスしか処理できないのに対し、Vera CPUは22,500以上を処理できる。AIエージェントが大量に並列稼働するシステムでは、このサンドボックス密度が直接コストと応答速度に影響する。
NVIDIA Vera CPUとは何か — Olympusコアの設計思想
Vera CPUの核心は、NVIDIAが独自開発した「Olympusコア」にある。これはNVIDIAが初めてゼロから設計したデータセンター向けCPUコアで、Arm v9.2-A命令セットをベースにしながら、AIエージェントのワークロードに特化した独自拡張を加えている。
従来のGrace CPUはArmのNeoverse V2コアをライセンスして使用していた。一般に認知度の高いArmアーキテクチャのコアを採用することで開発リスクを抑えるアプローチだったが、Veraではその制約を外した。NVIDIAの設計チームが独自に作り上げたOlympusコアは、AIエージェント処理に必要な以下の要素を最適化している。
- 10ウェイド命令フェッチ・デコード — 複数の独立したエージェントタスクを同時に処理するための広いパイプライン
- ニューラル分岐予測器 — 1サイクルあたり2分岐を評価でき、エージェントの複雑な制御フローを予測して待ち時間を削減
- NVIDIA Spatial Multithreading — 各コアが2つのタスクを同時実行。マルチテナント環境での一貫した予測可能なパフォーマンスを実現
- 6基の128ビットSVE2ベクターエンジン(FP8対応) — AIモデルのエージェント制御層で必要な演算を高効率で処理。世界初のFP8対応CPU
- 第2世代Scalable Coherency Fabric(SCF) — 3.4 TB/sのバイセクション帯域幅で、大規模ラック構成でもキャッシュコヒーレンシを維持
メモリ面でも革新がある。LPDDR5X SOCAMMモジュール(Small Outline Compression-Attached Memory Modules)を採用し、従来のDDRメモリと比べて消費電力を半分以下に抑えながら、1ソケットあたり最大1.5TBという大容量を実現した。長い文脈を処理するAIエージェントにとって、このメモリ容量の大きさは直接的なパフォーマンス向上につながる。
なぜ今「エージェント専用CPU」が必要なのか
AIの利用形態は大きく変わった。2022年から2024年にかけては「AIに聞く」時代だった。ユーザーが質問を入力し、AIが答えを返す。この形式では、処理の大半はGPUによる推論(モデルに入力を通して出力を得る計算)であり、CPUは補助的な役割に留まっていた。
しかし2025年以降、主流になりつつあるのは「AIがやる」時代だ。人間が指示を与えると、AIエージェントが自律的に複数のツールを呼び出し、判断を重ね、タスクを完了する。コーディングエージェント、調査エージェント、経理処理エージェント、顧客対応エージェント——こうした自律型AIは、ひとつのタスク完了までに何十回もの「ツール呼び出し」と「状態管理」を繰り返す。
この処理がなぜCPU負荷を高めるかというと、以下のような理由がある。GPUは「同じ演算をデータに対して大量並列に行う」ことが得意だ。行列演算や畳み込み演算がその典型で、これがニューラルネットワークの推論に適している。一方でAIエージェントが行うオーケストレーション処理は「分岐が多く、順序依存性が高く、外部I/Oが頻繁に発生する」処理だ。これはGPUが不得意とする領域であり、本質的にCPUが担うべき仕事だった。
GPUとCPUの役割分担(AIエージェント時代)
GPU 担当: テキスト生成・画像生成・音声認識など「モデルへの推論処理」。CPU 担当: エージェントのオーケストレーション、ツール呼び出し管理、サンドボックス制御、長い文脈のデータ検索・整合性確認。Vera CPUはこのCPU担当領域をAIエージェント向けに徹底最適化した。
問題は、従来のx86系CPUがこのAIエージェント処理に最適化されていなかったことだ。x86アーキテクチャはもともと汎用的な計算処理向けに設計されており、「多数の独立したエージェントが同時並行で動く」という特殊な負荷パターンには向いていない。NVIDIAが調査したところ、AIファクトリーの運用ではCPUがボトルネックとなるケースが増加しており、せっかくの高性能GPUがCPU待ちで遊んでしまうという問題が発生していた。Vera CPUはこの課題を根本から解決するための専用設計だ。
最初の導入先 — Anthropic・OpenAI・SpaceXAI・Oracleが選んだ理由
NVIDIAがVera CPUの初出荷先として選んだのは、世界でも有数のAI技術を持つ4組織だ。Anthropic(Claudeを開発)、OpenAI(ChatGPTを開発)、SpaceXAI(Grokを開発したxAIの関連組織)、そしてOracle Cloud Infrastructure(OCI)である。
これらの組織が共通して直面しているのが「AIエージェントの大規模運用」だ。Anthropicのシステムでは数千のClaudeエージェントが同時に動作し、OpenAIではo3やGPT-5を活用したエージェントが複雑なコード生成・テスト・デプロイサイクルを回している。SpaceXAIでもGrokエージェントが大量の並列タスクをこなしている。
OCIはさらに大規模な展開を計画している。同社は「数十万台のVera CPUを2026年中に導入する」と公表しており、企業向けのAIエージェントサービスの基盤として採用する方針だ。この規模感は、Vera CPUがニッチな用途向けではなく、企業AIインフラの主要コンポーネントとして位置づけられていることを示している。
| 導入組織 | 主な用途 | 展開規模 |
|---|---|---|
| Anthropic | Claudeエージェントのオーケストレーション・コード生成エージェント | 初期出荷(規模非公開) |
| OpenAI | ChatGPT・o3エージェントの並列処理・RL(強化学習)トレーニング | 初期出荷(規模非公開) |
| SpaceXAI | Grokエージェントのサンドボックス処理・ツール呼び出し管理 | 初期出荷(規模非公開) |
| Oracle Cloud Infrastructure | エンタープライズAIエージェントサービス基盤 | 2026年中に数十万台を計画 |
注目すべきはMetaの動向だ。Metaは独自のCPUを開発する一方で、NVIDIAのGrace CPUを本番環境に展開しており、Veraへの移行も視野に入れている。同社はCPUワークロードによっては2倍のperformance per watt改善を期待できると報告している。大手クラウドプロバイダー各社(Alibaba Cloud、CoreWeaveなど)もVera CPUの採用に向けて協議中であり、2026年下半期の一般提供開始(Dell、HPE、Lenovo、Supermicroなどのパートナーから)に合わせて、急速な普及が進む見通しだ。
GPU覇者NVIDIAがCPUを出した戦略的な意味
NVIDIAは長年「GPUメーカー」として知られてきた。ゲーム用GPUからスタートし、データセンター向けの高性能GPUでAI学習市場を席巻した。H100、H200、そしてBlackwell(B100、B200)シリーズで圧倒的なシェアを持つ。そのNVIDIAがCPUという異なる分野に本格参入することは、単なる製品拡張ではなく、根本的な戦略転換を意味する。
その理由は「フルスタック制御」にある。AIエージェントシステムにおいて、GPUは推論処理を担い、CPUはオーケストレーションを担う。これまでNVIDIAはGPU部分しかコントロールできなかった。しかしAIファクトリーの性能は「GPU×CPU」の組み合わせで決まる。優れたGPUを持ちながらCPU部分がボトルネックになるなら、顧客体験は悪化する。Vera CPUによってNVIDIAはAIファクトリーのGPU-CPU両方を最適化できるようになった。
さらに重要なのが「Vera Rubin NVL72」というシステム製品だ。Vera CPUは単独で販売されるだけでなく、次世代GPU「Rubin」とセットになった統合システムとして提供される。Vera CPUがRubin GPUに第2世代NVLink-C2Cインターフェース(1.8 TB/sの帯域幅)で直接接続されることで、CPUとGPUがほぼシームレスに連携できる。このCPU-GPU統合アーキテクチャは、Intelのプロセッサ上でNVIDIAのGPUを動かす従来の構成と比べて、大幅な効率向上をもたらす。
競合の観点からは、IntelとAMDへの直接的な挑戦でもある。これまでデータセンターCPU市場はIntel Xeonシリーズが長年支配し、AMD EPYCがシェアを伸ばしてきた。Vera CPUはAIエージェント処理という特定のニッチに特化することで、汎用CPUとの正面衝突を避けつつ、急成長するAIファクトリー市場を狙い撃ちにする戦略だ。NVIDIAはAI専用という差別化ポイントを武器に、汎用CPU市場の一角を切り取ろうとしている。
企業のAIインフラ整備への示唆 — クラウドとオンプレの選択
Vera CPUの登場は、これからAIエージェントを本格導入しようとしている企業にとって、重要な示唆を含んでいる。ただし、だからといって「今すぐVera CPUを自社で調達すべき」という話にはならない。中小企業から中堅企業の多くにとって、現時点で現実的な選択肢はクラウドサービスの活用だ。
Vera CPUを直接導入できるのは、当面の間、大手AIラボとクラウドプロバイダーに限られる。しかし、これらのクラウドプロバイダーがVera CPUを基盤にAIエージェントサービスを構築することで、企業ユーザーはVera CPUの恩恵をクラウド経由で間接的に受け取ることができる。AWS Bedrock、Azure AI、Google Cloud、Oracle Cloud Infrastructureなどのサービスを通じて、企業はVera CPU上で動くAIエージェント基盤を利用できるようになる見込みだ。
一方、大量のAIエージェントを社内環境で運用することを検討している組織(金融機関、医療機関、製造業の大企業など、データをクラウドに出せない制約がある場合)にとっては、オンプレミスでのVera CPU導入が将来的な選択肢になる。2026年下半期からDell、HPE、Supermicroなどのパートナー経由でVera CPUシステムが一般販売される予定のため、その時点での費用対効果の評価が重要になる。
クラウド vs オンプレ — AIエージェントインフラの選択基準
クラウド(推奨:初期段階) ── 初期投資ゼロ、最新ハードウェアへの即時アクセス、スケーラビリティ確保。OCIやAWSがVera CPUを基盤にサービスを展開予定。オンプレ(検討:大規模・機密データ要件あり) ── データを外部に出せない規制業種、長期的なコスト最適化が見込める大規模ユーザーに。2026年下半期からパートナー経由で購入可能。
どちらの経路を選ぶにしても、重要なのはAIエージェントのアーキテクチャ設計だ。ハードウェアは最適化されていく一方で、エージェントの設計が不適切だと性能を引き出せない。「どのタスクをエージェントに任せるか」「どのようなオーケストレーション戦略を採るか」「データの流れをどう設計するか」——これらのソフトウェア・設計レベルの問いに答えることが、ハードウェアの選定と同等かそれ以上に重要になる。
はてなベースのAI基盤構築支援との接続
はてなベースは、AIエージェントを業務に組み込む企業の支援を行っている。NVIDIA Vera CPUの登場は、私たちが取り組んでいる課題の核心部分を示している。AIエージェントが「答えるAI」から「動くAI」へ進化するにつれ、それを支えるインフラの設計と、エージェントそのものの設計の両方が重要になる。
経理部門でのAIエージェント活用(請求書処理、仕訳起票、月次レポート自動生成)、営業支援でのエージェント活用(リード管理、提案資料自動生成、フォローアップ管理)、社内ナレッジ管理でのエージェント活用(社内文書検索、Q&A自動対応)——これらのユースケースはいずれも、エージェントが複数のツールを呼び出しながら自律的に動くことを前提としている。
NVIDIA Vera CPUが可能にするのは、このようなエージェント処理を大規模かつ効率的に動かすインフラ基盤だ。そしてそのインフラの上で動くエージェントを、自社の業務フローに適合した形で設計・実装することが、企業としての競争優位につながる。ハードウェアの革新はその「入れ物」を整備するものであり、中身となるエージェントの設計こそが価値の源泉だ。
AIエージェントの業務導入を検討している方へ
NVIDIA Vera CPUのようなハードウェア革新が示すのは、AIエージェント時代が確実に到来しているということです。はてなベースでは、貴社の業務フローにAIエージェントを実装するための設計・構築・運用支援を行っています。クラウドを使った小規模実証から、オンプレ環境の本格導入まで対応します。まずは現状の課題をお聞かせください。
まとめ — ハードウェアからのAI革命が意味すること
NVIDIA Vera CPUの登場は、AIの進化がソフトウェアだけでなくハードウェアの層から加速していることを示す象徴的な出来事だ。88コアのカスタムOlympusコア、1.2 TB/sのメモリ帯域幅、x86比4倍のサンドボックス密度——これらのスペックは単なる数字ではなく、AIエージェントが実用規模で動ける環境が整いつつあることを意味している。
Anthropic、OpenAI、SpaceXAI、Oracleという世界最先端のAI組織が真っ先にVera CPUを採用したことは、この方向性が業界コンセンサスになっていることを示している。そしてOCIが「数十万台」規模での導入を計画していることは、企業向けAIエージェントサービスのインフラとして、Vera CPUが中核的な役割を担うことを予告している。
日本の企業にとっての実践的な次の一手は、このハードウェア基盤の上でどのようなAIエージェントを動かすかの設計を今から始めることだ。ハードウェアが整うのを待ってからエージェントを考えるのでは遅い。クラウドで小さく始め、エージェントのアーキテクチャを学び、業務への組み込みパターンを蓄積する——この積み重ねが、Vera CPUが一般化した未来において、競合に対して明確な優位を生む。
- Vera CPU(ベラCPU) — NVIDIAが開発したAIエージェント専用の初のCPU。88コアのOlympusコアを搭載し、2026年5月に初出荷
- Olympusコア — NVIDIAが独自設計したデータセンター向けCPUコア。Arm v9.2-A互換でFP8対応
- NVIDIA Spatial Multithreading — 1コアで2タスクを同時実行するNVIDIA独自の並列処理技術
- NVLink-C2C — CPUとGPUを高速・低遅延で接続するNVIDIA独自インターフェース。Vera CPUでは第2世代(1.8 TB/s)
- AIサンドボックス — AIエージェントが安全に外部ツールを呼び出すための隔離実行環境。エージェントの安全性に直結する概念
AI基盤の設計から運用まで、まとめて相談できます
「AIエージェントを導入したいが、何から始めていいかわからない」「既存の業務フローにどう組み込むかイメージが湧かない」——そうした段階から、はてなベースはご一緒します。まずは30分の無料相談から、貴社のAI導入の第一歩を踏み出しましょう。
AIエージェント開発の実行環境をお探しなら